Frequently asked questions¶
This section answers frequently asked questions about high-level DataLad concepts or commands. If you have a question you want to see answered in here, please create an issue or a pull request. For a series of specialized command snippets for various use cases, please see section Gists.
What is Git?¶
Git is a free and open source distributed version control system. In a directory that is initialized as a Git repository, it can track small-sized files and the modifications done to them. Git thinks of its data like a series of snapshots – it basically takes a picture of what all files look like whenever a modification in the repository is saved. It is a powerful and yet small and fast tool with many features such as branching and merging for independent development, checksumming of contents for integrity, and easy collaborative workflows thanks to its distributed nature.
DataLad uses Git underneath the hood. Every DataLad dataset is a Git
repository, and you can use any Git command within a DataLad dataset. Based
on the configurations in .gitattributes, file content can be version
controlled by Git or managed by git-annex, based on path pattern, file types,
or file size. The section More on DIY configurations details how these configurations work.
This chapter
gives a comprehensive overview on what Git is.
Where is Git’s “staging area” in DataLad datasets?¶
As mentioned in Populate a dataset, a local version control workflow with DataLad “skips” the staging area (that is typical for Git workflows) from the user’s point of view.
What is git-annex?¶
git-annex (https://git-annex.branchable.com/)
is a distributed file synchronization system written by Joey Hess. It can
share and synchronize large files independent from a commercial service or a
central server. It does so by managing all file content in a separate
directory (the annex, object tree, or key-value-store in .git/annex/objects/),
and placing only file names and
metadata into version control by Git. Among many other features, git-annex
can ensure sufficient amounts of file copies to prevent accidental data loss and
enables a variety of data transfer mechanisms.
DataLad uses git-annex underneath the hood for file content tracking and
transport logistics. git-annex offers an astonishing range of functionality
that DataLad tries to expose in full. That being said, any DataLad dataset
(with the exception of datasets configured to be pure Git repositories) is
fully compatible with git-annex – you can use any git-annex command inside a
DataLad dataset.
The chapter Under the hood: git-annex can give you more insights into how git-annex takes care of your data. git-annex’s website can give you a complete walk-through and detailed technical background information.
What does DataLad add to Git and git-annex?¶
DataLad sits on top of Git and git-annex and tries to integrate and expose their functionality fully. While DataLad thus is a “thin layer” on top of these tools and tries to minimize the use of unique/idiosyncratic functionality, it also tries to simplify working with repositories and adds a range of useful concepts and functions:
Both Git and git-annex are made to work with a single repository at a time. For example, while nesting pure Git repositories is possible via Git submodules (that DataLad also uses internally), cleaning up after placing a random file somewhere into this repository hierarchy can be very painful. A key advantage that DataLad brings to the table is that it makes the boundaries between repositories vanish from a user’s point of view. Most core commands have a
--recursiveoption that will discover and traverse any subdatasets and do-the-right-thing. Whereas git and git-annex would require the caller to first cd to the target repository, DataLad figures out which repository the given paths belong to and then works within that repository.datalad save . --recursive(manual) will solve the subdataset problem above, for example, no matter what was changed/added, no matter where in a tree of subdatasets.DataLad provides users with the ability to act on “virtual” file paths. If software needs data files that are carried in a subdataset (in Git terms: submodule) for a computation or test, a
datalad getwill discover if there are any subdatasets to install at a particular version to eventually provide the file content.DataLad adds metadata facilities for metadata extraction in various flavors, and can store extracted and aggregated metadata under
.datalad/metadata.
What kind of data is compatible with DataLad datasets?¶
Any information that can be expressed in digital files. This includes text files, tabular data, images, in any file format, and of any size and number.
What does a DataLad dataset contain? In what way is it “lightweight”?¶
Simply speaking, a DataLad dataset only contains metadata. Metadata on the identity and availability of data. On a computer with the DataLad software installed, a DataLad dataset looks like any other folder with files. However, file content is only obtained on-access. When file content needs to be accessed, it is downloaded from any of the known storage locations for a file. It can only be downloaded, if the requesting user has the necessary authorization to access a file.
Does DataLad host my data?¶
No, DataLad manages your data, but it does not host it. When publishing a dataset with annexed data, you will need to find a place that the large file content can be stored in – this could be a web server, a cloud service such as Dropbox, an S3 bucket, or many other storage solutions – and set up a publication dependency on this location. This gives you all the freedom to decide where your data lives, and who can have access to it. Once this set up is complete, publishing and accessing a published dataset and its data are as easy as if it would lie on your own machine. You can find a typical workflow in the chapter Third party infrastructure.
Is my data automatically “open” when I publish it with DataLad?¶
How openly your data is published is your choice. Combined with a fitting hosting provider, you can make all your data openly available, or available only partially, or to a specific audience, or only in the form of metadata.
Can I selectively publish only some data?¶
Yes. Or even just selected metadata.
How does GitHub relate to DataLad?¶
DataLad can make good use of GitHub, if you have figured out storage for your large files otherwise. You can make DataLad publish file content to one location and afterwards automatically push an update to GitHub, such that users can install directly from GitHub and seemingly also obtain large file content from GitHub. GitHub is also capable of resolving submodule/subdataset links to other GitHub repos, which makes for a nice UI.
Does DataLad scale to large dataset sizes?¶
In general, yes. The largest dataset managed by DataLad at this point is the Human Connectome Project data, encompassing 80 Terabytes of data in 15 million files, and larger projects (up to 500TB) are currently actively worked on. The chapter Go big or go home is a guide to “beyond-household-quantity datasets”.
What is the difference between a superdataset, a subdataset, and a dataset?¶
Conceptually and technically, there is no difference between a dataset, a
subdataset, or a superdataset. The only aspect that makes a dataset a sub- or
superdataset is whether it is registered in another dataset (by means of an entry in the
.gitmodules, automatically performed upon an appropriate datalad
clone -d or datalad create -d command) or contains registered datasets.
How can I convert/import/transform an existing Git or git-annex repository into a DataLad dataset?¶
You can transform any existing Git or git-annex repository of yours into a DataLad dataset by running:
$ datalad create -f
inside of it. Afterwards, you may want to tweak settings in .gitattributes
according to your needs (see sections DIY configurations and More on DIY configurations for
additional insights on this).
The chapter Better late than never guides you through transitioning an existing project into DataLad.
How can I convert an existing DataLad dataset with annexed data back to a plain Git repository?¶
If you decide to stop using git-annex or DataLad, or if you want to turn an annex repo back into a Git repo, you can do so with the git-annex uninit command. The section Getting all content out of the annex (removing the annex repo) contains more details.
What does DataLad cost?¶
DataLad is free and open source software. There are no fees, no running costs. A necessary investment is to learn how to use this tool.
Who develops DataLad?¶
DataLad is an international academic open source project with more than a hundred contributors, spearheaded by a US-German collaboration between Dartmouth College and the Research Centre Jülich.
How can I cite DataLad?¶
Please cite the official paper on DataLad:
Halchenko et al., (2021). DataLad: distributed system for joint management of code, data, and their relationship. Journal of Open Source Software, 6(63), 3262, https://doi.org/10.21105/joss.03262.
What is the difference between DataLad, Git LFS, and Flywheel?¶
Flywheel is an informatics platform for biomedical research and collaboration.
Git Large File Storage (Git LFS) is a command line tool that extends Git with the ability to manage large files. In that it appears similar to git-annex.
A more elaborate delineation from related solutions can be found in the DataLad developer documentation.
What is the difference between DataLad and DVC?¶
DVC is a version control system for machine learning projects. We have compared the two tools in a dedicated handbook section, Reproducible machine learning analyses: DataLad as DVC.
DataLad version-controls my large files – great. But how much is saved in total?¶
How can I copy data out of a DataLad dataset?¶
Moving or copying data out of a DataLad dataset is always possible and works in many cases just like in any regular directory. The only caveat exists in the case of annexed data: If file content is managed with git-annex and stored in the object-tree, what appears to be the file in the dataset is merely a symlink (please read section Data integrity for details). Moving or copying this symlink will not yield the intended result – instead you will have a broken symlink outside of your dataset.
When using the terminal command cp[1], it is sufficient to use the
-L/--dereference option. This will follow symbolic links, and make
sure that content gets moved instead of symlinks.
Remember that if you are copying some annexed content out of a dataset without
unlocking it first, you will only have “read” permissions on the files you have just
copied. Therefore you can :
- either unlock the files before copying them out,
- or copy them and then use the command chmod to be able to edit the file.
$ # this will give you 'write' permission on the file
$ chmod +w filename
If you are not familiar with how the chmod works (or if you forgot - let’s be honest we
all google it sometimes), this is a nice tutorial .
With tools other than cp (e.g., graphical file managers), to copy or move
annexed content, make sure it is unlocked first:
After a datalad unlock (manual) copying and moving contents will work fine.
A subsequent datalad save in the dataset will annex the content
again.
Is there Python 2 support for DataLad?¶
No, Python 2 support has been dropped in September 2019.
Is there a graphical user interface for DataLad?¶
Yes, a dedicated DataLad extension, datalad-gooey, provides a graphical user interface for DataLad.
You can read more about it in the section DataLad in a graphical user interface.
How does DataLad interface with OpenNeuro?¶
OpenNeuro is a free and open platform for sharing MRI,
MEG, EEG, iEEG, and ECoG data. It publishes hosted data as DataLad datasets on
GitHub. The entire collection can be found at
github.com/OpenNeuroDatasets. You can
obtain the datasets just as any other DataLad datasets with datalad clone (manual)
or datalad install (manual).
There is more info about this in the OpenNeuro Quickstart Guide.
How does DataLad process the data given to it?¶
DataLad does not modify file content, or enforce a particular data organization inside a dataset. From a user-perspective, a DataLad dataset is a regular directory on a computer’s file system. This directory is populated with files that a user has placed into this directory. DataLad manages identity information of these files over time (version controlled content identifiers, typically based on checksums). DataLad also assists with file transport (upload/download) to and from this directory, and tracks the associated file content availability metadata. Users may also associate arbitrary additional metadata with any file content or dataset version. Any and all metadata and DataLad-internal management information is kept separate from the managed content, but located inside the managed directory (in a .git subdirectory). No information is transmitted to a location outside this local directory, unless a user explicitly performs such an action. DataLad is agnostic with respect to the content of a file it manages within a dataset. DataLad reads all file content in binary form for the sole purpose of computing a content identifier, which is typically based on a checksum (e.g., MD5 or SHA1). This content identifier is used to associate file content availability and other metadata. DataLad supports the execution of user-defined, user-provided metadata extractor algorithms. These software components can process files of a particular format, in order to derive metadata from it. Volume, format and terminology of such metadata are determined by the provider of an extractor implementation, and a user’s parameterization. DataLad also supports the execution of user-defined programs and scripts. When executed through DataLad, users can record inputs and parameters of such a process, and DataLad can capture the identity of any generated output files. This enables metadata-based queries on the origin of files, and programmatic recomputing.
BIDS validator issues in datasets with missing file content¶
As outlined in section Data integrity, all unretrieved files in datasets are broken symlinks.
This is desired, and not a problem per se, but some tools, among them the BIDS validator, can be confused by this.
Should you attempt to validate a dataset in which all or some file contents are missing, for example after cloning a dataset or after dropping file contents, the validator may fail to report on the validity of the complete dataset or the specific unretrieved files.
If you aim for a complete validation of your dataset, re-do the validation after retrieving all necessary file contents.
If you only aim to validate file names and structure, invoke the bids validator with the additional flags --ignoreNiftiHeaders and --ignoreSymlinks.
What is the git-annex branch?¶
If your DataLad dataset contains an annex, there is also a git-annex branch
that is created, used, and maintained solely by git-annex. It is completely
unconnected to any other branches in your dataset, and contains different types
of log files.
The contents of this branch are used for git-annex internal tracking of the
dataset and its annexed contents. For example, git-annex stores information where
file content can be retrieved from in a .log file for each object, and if the object
was obtained from web-sources (e.g., with datalad download-url (manual)), a
.log.web file stores the URL. Other files in this branch store information about
the known remotes of the dataset and their description, if they have one.
You can find out much more about the git-annex branch and its contents in the
documentation.
This branch, however, is managed by git-annex, and you should not tamper with it.
Help - Why does Github display my dataset with git-annex as the default branch?¶
If your dataset is represented on GitHub with cryptic directories instead of actual file names, GitHub probably declared the git-annex branch to be your repositories “default branch”. Here is an example:
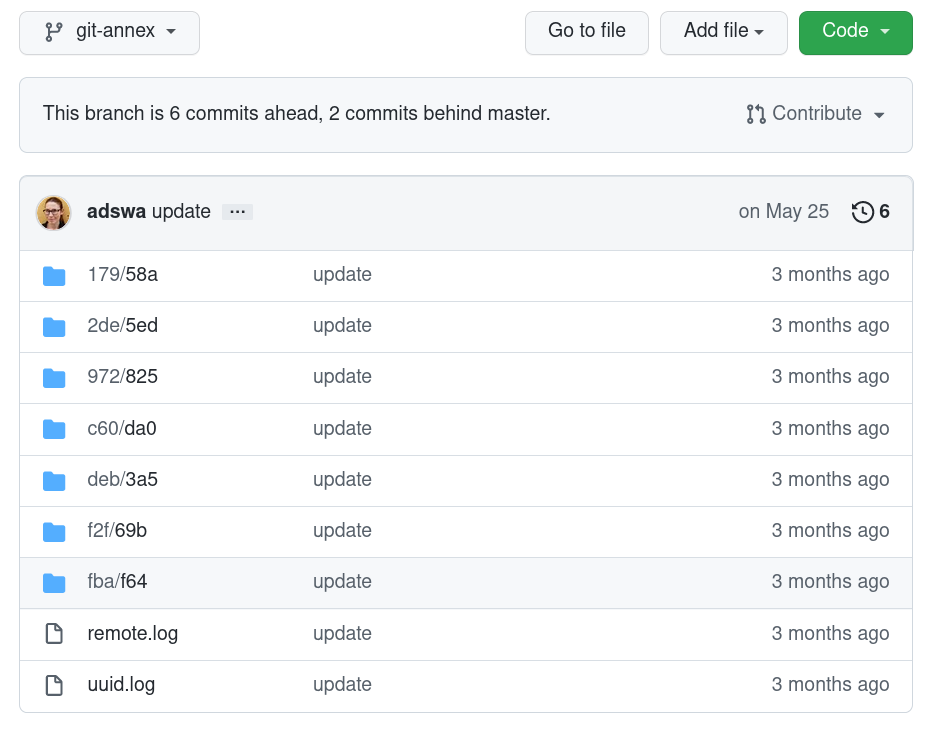
This is related to GitHub’s decision to make main the default branch for newly created repositories – datasets that do not have a main branch (but, for example, a master branch) may end up with a different branch being displayed on GitHub than intended.
To fix this for present and/or future datasets, the default branch can be configured to a branch name of your choice on a repository- or organizational level via GitHub’s web-interface.
Alternatively, you can rename existing master branches into main using git branch -m master main (but beware of unforeseen consequences - your collaborators may try to update the master branch but fail, continuous integration workflows could still try to use master, etc.).
Lastly, you can initialize new datasets with main instead of master – either with a global Git configuration[2] for init.defaultBranch (git config --global init.defaultBranch main), or by passing the --initial-branch <branchname> option via datalad create by appending --initial-branch main to the command (datalad create mydataset --initial-branch main)[3].
Footnotes