Contributing¶
Thanks for being curious about contributing! We greatly appreciate and welcome contributions to this book, be it in the form of an issue, quick feedback on DataLad’s usability, a pull request, or a discussion you had with anyone on the team via a non-GitHub communication channel! To find out how we acknowledge contributions, please read the paragraph Acknowledging Contributors at the bottom of this page.

If you are considering doing a pull request: Great! Every contribution is valuable, from fixing typos to writing full chapters. The steps below outline how the book “works”. It is recommended to also create an issue to discuss changes or additions you plan to make in advance.
Software setup¶
An automatically triggered continuous integration setup will build the handbook (i.e., execute all code snippets in the “Basics” section, and assemble everything into a rendered book) when you open a pull request. Depending on the size of your contribution, you may want to be able to build the book locally to test and preview your changes. If you are fixing typos, tweak the language, or rewrite a paragraph or two, this should not be necessary, and you can safely skip this paragraph and instead take a look into the paragraph Easy pull requests. If you want to be able to build the book locally, though, please follow these instructions:
datalad install the repository recursively. This ensures that dependent subdatasets are installed as well
$ datalad install -r https://github.com/datalad-handbook/book.git
optional, but recommended: Create a virtual environment
$ virtualenv --python=python3 ~/env/handbook
$ . ~/env/handbook/bin/activate
install the requirements and a custom Python helper for the handbook
# navigate into the installed dataset
$ cd book
# install required software
$ pip install -r requirements.txt
$ pip install -r requirements-devel.txt
install
librsvg2-bin(a tool to render.svgs) with your package manager
$ sudo apt-get install librsvg2-bin
The code examples that need to be executed to build the book (see also the paragraph “Code” in
Directives and demos to learn more about this) are executed inside of
the directory define by the environment variable AUTORUNRECORD_BASEDIR.
This can be any directory, and it is advisable to use a temporary directory.
Essentially, this directory is a mock HOME directory. The build is set up to yield
identical paths in code snippets regardless of the machine the book is built on: Else, code snippets
created on one machine might have the path /home/adina, and others created on
a second machine /home/mih, for example, leading to some potential confusion for readers.
Therefore, you need to create this directory, and also –
for consistency – define a minimal Git configuration for the mock handbook user
(we chose Elena Piscopia, the first
woman to receive a PhD. Do not worry, this does not mess with your own Git identity):
$ export AUTORUNRECORD_BASEDIR=/tmp/handbook_workdir
$ tools/bootstrap-handbook-user
Once this is configured, you can build the book locally by running make build in the root
of the repository, and open it in your browser, for example with
firefox docs/_build/html/index.html.
In case you need to remove the build files, you can just run make clean-build.
Automatic builds¶
When you do not build the handbook locally, but add a new runrecord (see also the paragraph “Code” in Directives and demos to learn more about this) or change an existing one, the Appveyor CI build will execute the code snippet for you.
After the Appveyor build completed successfully, it will upload every changed or new code snippet as a build artifact.
You can download this artifact and add the diff by running the following command in your local clone of the handbook repository:
$ wget https://ci.appveyor.com/api/projects/mih/book/artifacts/runrecord_diff.txt \
-O - | git apply
Inspect the changes, commit then, and push them into your PR.
Directives and demos¶
If you are writing larger sections that contain code, gitusernotes, findoutmores,
or other special directives, please make sure that you read this paragraph.
The book is build with a number of custom directives. If applicable, please use them in the same way they are used throughout the book.
Code: For code that runs inside a dataset such as DataLad-101,
working directories exist inside of $AUTORUNRECORD_BASEDIR. The DataLad-101
dataset for example lives in $AUTORUNRECORD_BASEDIR/dl-101. This comes with the advantage
that code is tested immediately – if the code snippet contains an error, this error will
be written into the book, and thus prevent faulty commands from being published.
Running code in a working directory will furthermore build up on the existing history
of this dataset, which is very useful if some code relies on working with previously
created content or dataset history. Build code snippets that add to these working directories
by using the runrecord directive. Commands wrapped in these will write the output
of a command into example files stored inside of the DataLad Handbook repository clone
in docs/PART/_examples (where PART is basics, beyond_basics, or usecases).
Make sure to name these files according to the following
schema, because they are executed sequentially:
_examples/DL-101-1<nr-of-section>-1<nr-of-example>, e.g.,
_examples/DL-101-101-101 for the first example in the first section
of the given part.
Here is how a runrecord directive can look like:
.. runrecord:: _examples/DL-101-101-101 # give the path to the resulting file, start with _examples
:language: console
# specify a working directory here.
# This translates to $AUTORUNRECORD_BASEDIR/dl-101/DataLad-101
:workdir: dl-101/DataLad-101
# this is a comment
$ this line will be executed
Afterwards, the resulting example files need to be committed into Git. To clear existing
examples in docs/PART/_examples and the mock directories in $AUTORUNRECORD_BASEDIR, run
make clean (to remove working directories and examples for all parts of the book)
or make clean-examples (to remove only examples and workdirs of the Basics part).
However, for simple code snippets outside of the narrative of DataLad-101,
simple code-block:: directives are sufficient.
Other custom directives: Other custom directives are gitusernote
(for additional Git-related information for Git-users), and findoutmore
(foldable sections that contain content that goes beyond the basics). Make use
of them, if applicable to your contribution.
Creating live code demos out of runrecord directives: The book has the capability to turn code snippets into a script that the tool cast_live can use to cast and execute it in a demonstration shell. This feature is intended for educational courses and other types of demonstrations. The following prerequisites exist:
A snippet only gets added to a cast, if the
:cast:option in therunrecordspecifies a filename where to save the demo to (it does not need to be an existing file).If
:realcommand:options are specified, they will become the executable part of the cast. If note, the code snippet in the code-block of therunrecordwill become the executable part of the cast.An optional
:notes:lets you add “speakernotes” for the cast.Demos are produced upon
make, but only if the environment variableCAST_DIRis set. This should be a path that points to any directory in which demos should be created and saved. An invocation could look like this:$ CAST_DIR=$AUTORUNRECORD_BASEDIR/casts make
This is a fully specified runrecord:
.. runrecord:: _examples/DL-101-101-101
:language: console
:workdir: dl-101/DataLad-101
:cast: dataset_basics # name of the cast file (will be created/extended in CAST_DIR)
:notes: This is an optional speaker note only visible to presenter during the cast
# this is a comment and will be written to the cast
$ this line will be executed and written to the cast
IMPORTANT! Code snippets will be turned into casts in the order of
execution of runrecords. If you are adding code into an existing cast,
i.e., in between two snippets that get written to the same cast, make sure that
the cast will still run smoothly afterwards!
Running live code demos from created casts:
If you have created a cast, you can use the tool live_cast in tools/ in
the DataLad Course to
execute them:
~ course$ tools/cast_live path/to/casts
The section Teaching with the DataLad Handbook outlines more on this and other teaching materials the handbook provides.
Easy pull requests¶
The easiest way to do a pull request is within the web-interface that GitHub
and readthedocs provide. If you visit the rendered
version of the handbook at handbook.datalad.org
and click on the small, floating v:latest element at the lower
right-hand side, the Edit option will take you straight to an editor that
lets you make your changes and submit a pull request.
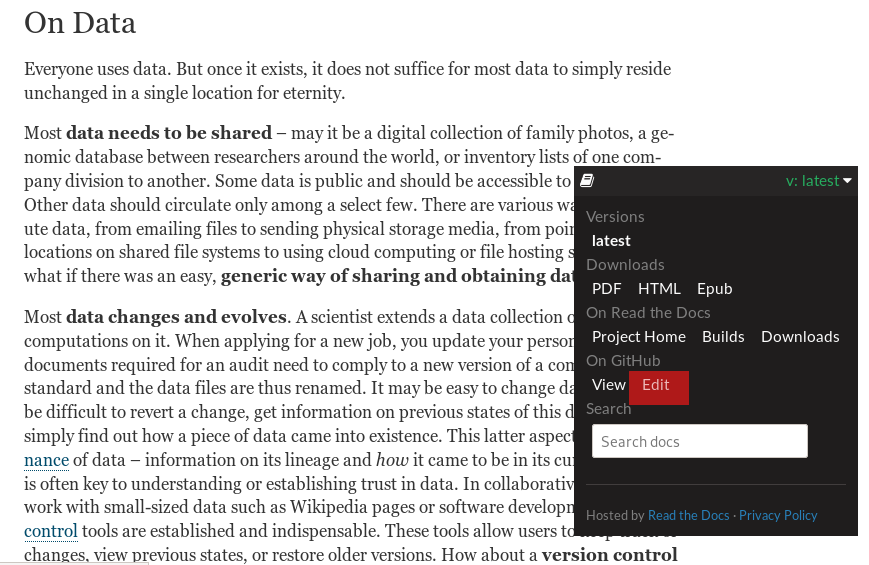
Fig. 3 You can find an easy way to submit a pull request right from within the handbook.¶
But you of course are also welcome to submit a pull request with whichever other workflow suites you best.
Desired structure of the book¶
The book consists of four major parts: Introduction, Basics, Beyond Basics, and Use Cases, plus an appendix. Purpose and desired content of these parts are outlined below. When contributing to one of these sections, please make sure that your contribution stays in the scope of the respective section.
Introduction¶
An introduction to DataLad, and the problems it aims to be a solution for.
This part is practically free of hands-on content, i.e., no instructions, no demos. Instead, it is about concepts, analogies, general problems.
In order to avoid too much of a mental split between a reader’s desire to learn how to actually do things vs. conceptual information, the introduction is purposefully kept short and serves as a narrated table of contents with plenty of references to other parts of the book.
Basics¶
This part contains hands-on-style content on skills that are crucial for using DataLad productively. It aims to be a continuous tutorial after which readers are able to perform the following tasks:
Create and populate own datasets from scratch
Consume existing datasets
Share datasets on shared an third party infrastructure and collaborate
Execute commands or scripts (computationally) reproducible
Configure datasets or DataLad operations as needed
Use DataLad’s metadata capabilities
The order of topics in this part is determined by the order in which they become relevant for a novice DataLad user.
Content should be written in a way that explicitly encourages executing the shown commands, up to simple challenges (such as: “find out who the author of the first commit in the installed subdataset XY is”).
Beyond Basics¶
This part goes beyond the Basics and is a place for documenting advanced or special purpose commands or workflows. Examples for this sections are: Introductions to special-purpose extensions, hands-on technical documentation such as “how to write your own DataLad extension”, or rarely encountered use cases for DataLad, such as datasets for large-scale projects.
This section contains chapters that are disconnected from each other, and not related to any narrative. Readers are encouraged to read chapters or sections that fit their needs in whichever order they prefer.
Care should be taken to not turn content that could be a use case into an advanced chapter.
Use Cases¶
Topics that do not fit into the introduction or basics parts, but are DataLad-centric, go into this part. Ideal content are concrete examples of how DataLad’s concepts and building blocks can be combined to implement a solution to a problem.
Any chapter is written as a more-or-less self-contained document that can make frequent references to introduction and basics, but only few, and more general ones to other use cases. This should help with long-term maintenance of the content, as the specifics of how to approach a particular use case optimally may evolve over time, and cross-references to specific functionality might become invalid.
There is no inherent order in this part, but chapters may be grouped by domain, skill-level, or DataLad functionality involved (or combinations of those).
Any content in this part can deviate from the examples and narrative used for introduction and basics whenever necessary (e.g., concrete domain specific use cases). However, if possible, common example datasets, names, terms should be adopted, and the broadest feasible target audience should be assumed. Such more generic content should form the early chapters in this part.
Unless there is reason to deviate, the following structure should be adopted:
Summary/Abstract (no dedicated heading)
The Challenge: description what problem will be solved, or which conditions are present when DataLad is not used
The DataLad Approach: high-level description how DataLad can be used to address the problem at hand.
Step-by-Step: More detailed illustration on how the “DataLad approach” can be implemented, ideally with concrete code examples.
Intersphinx mapping¶
The handbook tries to provide stable references to commands, concepts,
and use cases for
Intersphinx Mappings.
This can help to robust-ify links – instead of long URLs that are dependent
on file or section titles, or references to numbered sections (both can break
easily), intersphinx references are meant to stick to contents and reliably point
to it via a mapping in the index
under Symbols. An example intersphinx mapping is done
in DataLad.
The references take the following shape: .. _1-001:
The leading integer indicates the category of reference:
1: Command references
2: Concept references
3: Use case references
The later integers are consecutively numbered in order of creation. If you want to create a new reference, just create a reference one integer higher than the previously highest. The currently existing intersphinx references are:
1-001: DataLad cheat sheet
1-002: DataLad, run!
2-002: Data integrity
2-003: DataLad’s result hooks
3-001: Building a scalable data storage for scientific computing
Tweaking the CSS of the book¶
The custom CSS of the book is controlled by the file docs/_static/custom.css.
If you have build the book locally by running make build,
you can directly tweak the custom CSS file in docs/_build/html/_static/custom.css
to view the changes without having to rebuild the book.
But once you have found the proper CSS style you are happy with
make sure to save and commit those changes in docs/_static/custom.css
Acknowledging Contributors¶
If you have helped this project, we would like to acknowledge your contribution in the GitHub repository in our README with allcontributors.org, and the project’s .zenodo (you can add yourself as second-to-last, i.e. just above Michael) and CONTRIBUTORS.md files. The allcontributors bot will give credit for various types of contributions. We may ask you to open a PR to add yourself to all of our contributing acknowledgements or do it ourselves and let you know.