9.3. Back and forth in time¶
Almost everyone inadvertently deleted or overwrote files at some point with a hasty operation that caused data fatalities or at least troubles to reobtain or restore data. With DataLad, no mistakes are forever: One powerful feature of datasets is the ability to revert data to a previous state and thus view earlier content or correct mistakes. As long as the content was version controlled (i.e., tracked), it is possible to look at previous states of the data, or revert changes – even years after they happened – thanks to the underlying version control system Git.

To get a glimpse into how to work with the history of a dataset, today’s lecture has an external Git-expert as a guest lecturer. “I do not have enough time to go through all the details in only one lecture. But I’ll give you the basics, and an idea of what is possible. Always remember: Just google what you need. You will find thousands of helpful tutorials or questions on Stack Overflow right away. Even experts will constantly seek help to find out which Git command to use, and how to use it.”, he reassures with a wink.
The basis of working with the history is to look at it with tools such
as tig, gitk, or simply the git log (manual) command.
The most important information in an entry (commit) in the history is
the shasum (or hash) associated with it.
This hash is how dataset modifications in the history are identified,
and with this hash you can communicate with DataLad or Git about these
modifications or version states[1].
Here is an excerpt from the DataLad-101 history to show a
few abbreviated hashes of the 15 most recent commits[2]:
$ git log -15 --oneline
23072dd remove obsolete subds
50359f3 [DATALAD] Added subdataset
f7a31cb save cropped logos to Git
c7f94fa move book back from midterm_project
d8a4aec move book into midterm_project
ba91786 add container and execute analysis within container
ebc300e finished my midterm project
efc0ab0 [DATALAD] Recorded changes
c403f14 add note on DataLad's procedures
39c928e add note on configurations and git config
4beb2bc Add note on adding siblings
6343867 Merge remote-tracking branch 'roommate/main'
822bf54 add note about datalad update
191e2a3 Include nesting demo from datalad website
d664af1 add note on git annex whereis
“I’ll let you people direct this lecture”, the guest lecturer proposes. “You tell me what you would be interested in doing, and I’ll show you how it’s done. For the rest of the lecture, call me Google!”
9.3.1. Fixing (empty) commit messages¶
From the back of the lecture hall comes a question you are really glad
someone asked: “It has happened to me that I accidentally did a
datalad save (manual) and forgot to specify the commit message,
how can I fix this?”.
The room nods in agreement – apparently, others have run into this
premature slip of the Enter key as well.
Let’s demonstrate a simple example. First, let’s create some random files. Do this right in your dataset.
$ cat << EOT > Gitjoke1.txt
Git knows what you did last summer!
EOT
$ cat << EOT > Gitjoke2.txt
Knock knock. Who's there? Git.
Git-who?
Sorry, 'who' is not a git command - did you mean 'show'?
EOT
$ cat << EOT > Gitjoke3.txt
In Soviet Russia, git commits YOU!
EOT
This will generate three new files in your dataset. Run a
datalad status (manual) to verify this:
$ datalad status
untracked: Gitjoke1.txt (file)
untracked: Gitjoke2.txt (file)
untracked: Gitjoke3.txt (file)
And now:
$ datalad save
add(ok): Gitjoke1.txt (file)
add(ok): Gitjoke2.txt (file)
add(ok): Gitjoke3.txt (file)
save(ok): . (dataset)
Whooops! A datalad save without a
commit message that saved all of the files.
$ git log -p -1
commit 59bb8460✂SHA1
Author: Elena Piscopia <elena@example.net>
Date: Tue Jun 18 16:13:00 2019 +0000
[DATALAD] Recorded changes
diff --git a/Gitjoke1.txt b/Gitjoke1.txt
new file mode 100644
index 0000000..d7e1359
--- /dev/null
+++ b/Gitjoke1.txt
@@ -0,0 +1 @@
+Git knows what you did last summer!
diff --git a/Gitjoke2.txt b/Gitjoke2.txt
new file mode 100644
index 0000000..51beecb
--- /dev/null
+++ b/Gitjoke2.txt
@@ -0,0 +1,3 @@
+Knock knock. Who's there? Git.
+Git-who?
+Sorry, 'who' is not a git command - did you mean 'show'?
diff --git a/Gitjoke3.txt b/Gitjoke3.txt
new file mode 100644
index 0000000..7b83d95
--- /dev/null
+++ b/Gitjoke3.txt
@@ -0,0 +1 @@
+In Soviet Russia, git commits YOU!
As expected, all of the modifications present prior to the
command are saved into the most recent commit, and the commit
message DataLad provides by default, [DATALAD] Recorded changes,
is not very helpful.
Changing the commit message of the most recent commit can be done with
the command git commit --amend (manual). Running this command will open
an editor (the default, as configured in Git), and allow you
to change the commit message. Make sure to read the find-out-more on changing other than the most recent commit in case you want to improve the commit message of more commits than only the latest.
Try running the git commit --amend command right now and give
the commit a new commit message (you can just delete the one created by
DataLad in the editor)!
‘git commit –amend’ versus ‘datalad save –amend’
Similar to git commit, datalad save also has an --amend option.
Like its Git equivalent, it can be used to record changes not in a new, separate commit, but integrate them with the previously saved state.
Though this has not been the use case for git commit --amend here, experienced Git users will be accustomed to using git commit --amend to achieve something similar in their Git workflows.
In contrast to git commit --amend, datalad save --amend will not open up an interactive editor to potentially change a commit message (unless the configuration datalad.save.no-message is set to interactive), but a new commit message can be supplied with the -m/--message option.
Changing the commit messages of not-the-most-recent commits
The git commit --amend command will let you
rewrite the commit message of the most recent commit. If you
however need to rewrite commit messages of older commits, you
can do so during a so-called “interactive rebase”. The command
for this is
$ git rebase -i HEAD~N
where N specifies how far back you want to rewrite commits.
git rebase -i HEAD~3, for example, lets you apply changes to the
any number of commit messages within the last three commits.
Be aware that an interactive rebase lets you rewrite history. This can lead to confusion or worse if the history you are rewriting is shared with others, e.g., in a collaborative project. Be also aware that rewriting history that is pushed/published (e.g., to GitHub) will require a force-push!
Running this command gives you a list of the N most recent commits in your text editor (which may be vim!), sorted with the most recent commit on the bottom. This is how it may look like:
pick 8503f26 Add note on adding siblings
pick 23f0a52 add note on configurations and git config
pick c42cba4 add note on DataLad's procedures
# Rebase b259ce8..c42cba4 onto b259ce8 (3 commands)
#
# Commands:
# p, pick <commit> = use commit
# r, reword <commit> = use commit, but edit the commit message
# e, edit <commit> = use commit, but stop for amending
# s, squash <commit> = use commit, but meld into previous commit
# f, fixup <commit> = like "squash", but discard this commit's log message
# x, exec <command> = run command (the rest of the line) using shell
# b, break = stop here (continue rebase later with 'git rebase --continue')
# d, drop <commit> = remove commit
# l, label <label> = label current HEAD with a name
An interactive rebase allows to apply various modifying actions to any
number of commits in the list. Below the list are descriptions of these
different actions. Among them is “reword”, which lets you “edit the commit
message”. To apply this action and reword the top-most commit message in this list
(8503f26 Add note on adding siblings, three commits back in the history),
exchange the word pick in the beginning of the line with the word
reword or simply r like this:
r 8503f26 Add note on adding siblings
If you want to reword more than one commit message, exchange several
picks. Any commit with the word pick at the beginning of the line will
be kept as is. Once you are done, save and close the editor. This will
sequentially open up a new editor for each commit you want to reword. In
it, you will be able to change the commit message. Save to proceed to
the next commit message until the rebase is complete.
But be careful not to delete any lines in the above editor view –
An interactive rebase can be dangerous, and if you remove a line, this commit will be lost!
9.3.2. Untracking accidentally saved contents (tracked in Git)¶
The next question comes from the front:
“It happened that I forgot to give a path to the datalad save
command when I wanted to only start tracking a very specific file.
Other times I just didn’t remember that
additional, untracked files existed in the dataset and saved unaware of
those. I know that it is good practice to only save
those changes together that belong together, so is there a way to
disentangle an accidental datalad save again?”
Let’s say instead of saving all three previously untracked Git jokes you intended to save only one of those files. What we want to achieve is to keep all of the files and their contents in the dataset, but get them out of the history into an untracked state again, and save them individually afterwards.
Untracking is different for Git versus git-annex!
Note that this is a case with text files (stored in Git)! For accidental annexing of files, please make sure to check out the next paragraph!
This is a task for the git reset (manual) command. It essentially allows to
undo commits by resetting the history of a dataset to an earlier version.
git reset comes with several modes that determine the
exact behavior it, but the relevant one for this aim is --mixed[3].
Specifying the command:
$ git reset --mixed COMMIT
will preserve all changes made to files since the specified
commit in the dataset but remove them from the dataset’s history.
This means all commits since COMMIT (but not including COMMIT)
will not be in your history anymore and become “untracked files” or
“unsaved changes” instead. In other words, the modifications
you made in these commits that are “undone” will still be present
in your dataset – just not written to the history anymore. Let’s
try this to get a feel for it.
The COMMIT in the command can either be a hash or a reference with the HEAD pointer.
Git terminology: branches and HEADs?
A Git repository (and thus any DataLad dataset) is built up as a tree of
commits. A branch is a named pointer (reference) to a commit, and allows you
to isolate developments. The default branch is called main. HEAD is
a pointer to the branch you are currently on, and thus to the last commit
in the given branch.
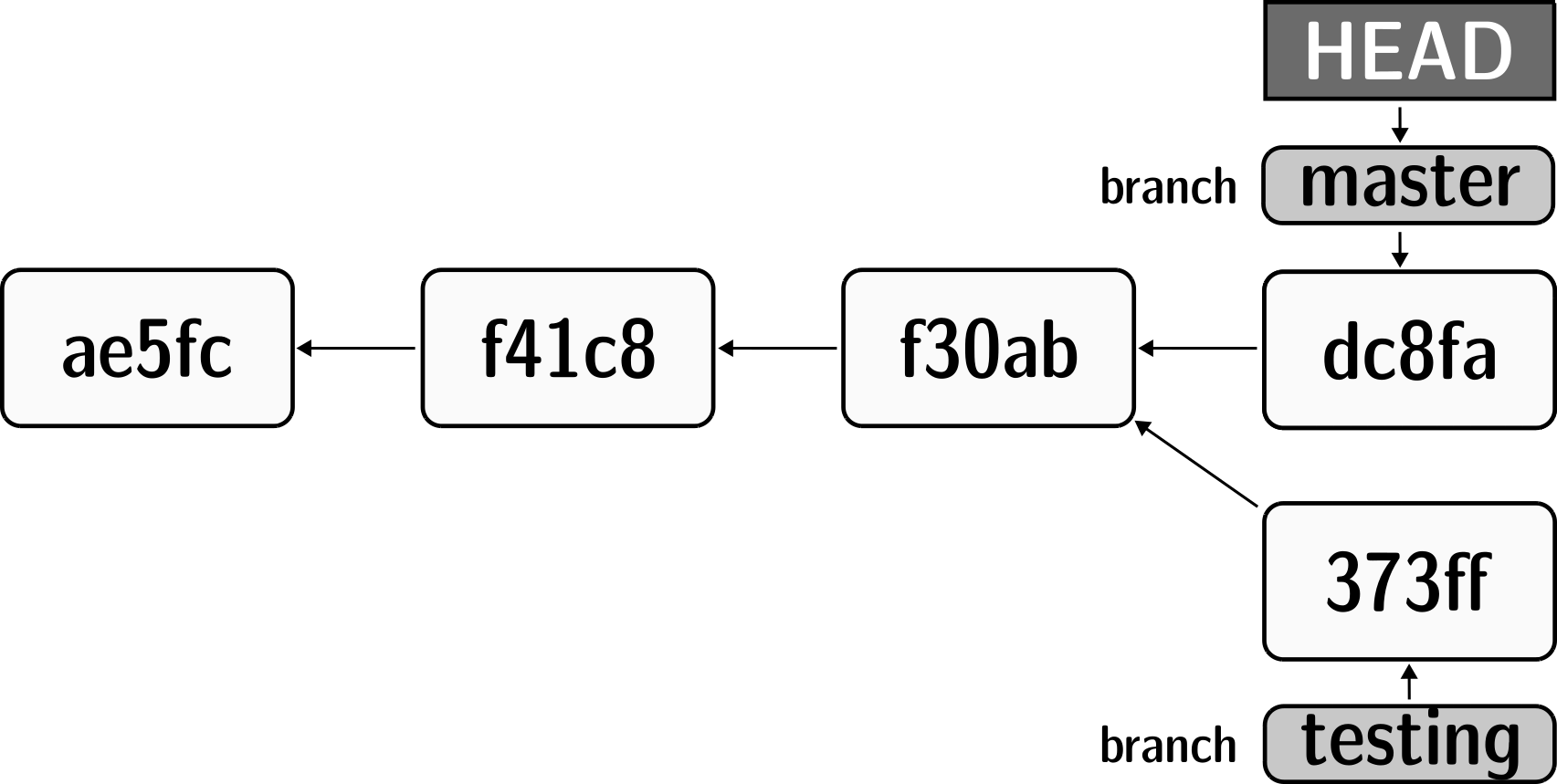
Using HEAD, you can identify the most recent commit, or count backwards
starting from the most recent commit. HEAD~1 is the ancestor of the most
recent commit, i.e., one commit back (f30ab in the figure above). Apart from
the notation HEAD~N, there is also HEAD^N used to count backwards, but
less frequently used and of importance primarily in the case of merge
commits.
Let’s stay with the hash, and reset to the commit prior to saving the Git jokes.
First, find out the shasum, and afterwards, reset it.
$ git log -n 3 --oneline
59bb846 [DATALAD] Recorded changes
23072dd remove obsolete subds
50359f3 [DATALAD] Added subdataset
$ git reset --mixed 23072dd3✂SHA1
Let’s see what has happened. First, let’s check the history:
$ git log -n 2 --oneline
23072dd remove obsolete subds
50359f3 [DATALAD] Added subdataset
As you can see, the commit in which the jokes were tracked
is not in the history anymore! Go on to see what datalad status
reports:
$ datalad status
untracked: Gitjoke1.txt (file)
untracked: Gitjoke2.txt (file)
untracked: Gitjoke3.txt (file)
Nice, the files are present, and untracked again. Do they contain
the content still? We will read all of them with cat:
$ cat Gitjoke*
Git knows what you did last summer!
Knock knock. Who's there? Git.
Git-who?
Sorry, 'who' is not a git command - did you mean 'show'?
In Soviet Russia, git commits YOU!
Great. Now we can go ahead and save only the file we intended to track:
$ datalad save -m "save my favorite Git joke" Gitjoke2.txt
add(ok): Gitjoke2.txt (file)
save(ok): . (dataset)
Finally, let’s check how the history looks afterwards:
$ git log -2
commit f7863f37✂SHA1
Author: Elena Piscopia <elena@example.net>
Date: Tue Jun 18 16:13:00 2019 +0000
save my favorite Git joke
commit 23072dd3✂SHA1
Author: Elena Piscopia <elena@example.net>
Date: Tue Jun 18 16:13:00 2019 +0000
remove obsolete subds
Wow! You have rewritten history[4]!
9.3.3. Untracking accidentally saved contents (stored in git-annex)¶
The previous git reset undid the tracking of text files.
However, those files are stored in Git, and thus their content
is also stored in Git. Files that are annexed, however, have
their content stored in git-annex, and not the file itself is stored
in the history, but a symlink pointing to the location of the file
content in the dataset’s annex. This has consequences for
a git reset command: Reverting a save of a file that is
annexed would revert the save of the symlink into Git, but it will
not revert the annexing of the file.
Thus, what will be left in the dataset is an untracked symlink.
To undo an accidental save of that annexed a file, the annexed file
has to be “unlocked” first with a datalad unlock (manual) command.
We will simulate such a situation by creating a PDF file that
gets annexed with an accidental datalad save:
$ # create an empty pdf file
$ convert xc:none -page Letter apdffile.pdf
$ # accidentally save it
$ datalad save
add(ok): Gitjoke1.txt (file)
add(ok): Gitjoke3.txt (file)
add(ok): apdffile.pdf (file)
save(ok): . (dataset)
This accidental datalad save has thus added both text files
stored in Git, but also a PDF file to the history of the dataset.
As an ls -l reveals, the PDF file has been annexed and is
thus a symlink:
$ ls -l apdffile.pdf
lrwxrwxrwx 1 elena elena 122 2019-06-18 16:13 apdffile.pdf -> .git/annex/objects/P8/mG/✂/MD5E-s1216--5cd525d3✂MD5.pdf
Prior to resetting, the PDF file has to be unannexed.
To unannex files, i.e., get the contents out of the object tree,
the datalad unlock command is relevant:
$ datalad unlock apdffile.pdf
unlock(ok): apdffile.pdf (file)
The file is now no longer symlinked:
$ ls -l apdffile.pdf
-rw-r--r-- 1 elena elena 1216 2019-06-18 16:13 apdffile.pdf
Finally, git reset --mixed can be used to revert the
accidental datalad save. Again, find out the shasum first, and
afterwards, reset it.
$ git log -n 3 --oneline
0079afc [DATALAD] Recorded changes
f7863f3 save my favorite Git joke
23072dd remove obsolete subds
$ git reset --mixed f7863f37✂SHA1
To see what has happened, let’s check the history:
$ git log -n 2 --oneline
f7863f3 save my favorite Git joke
23072dd remove obsolete subds
… and also the status of the dataset:
$ datalad status
untracked: Gitjoke1.txt (file)
untracked: Gitjoke3.txt (file)
untracked: apdffile.pdf (file)
The accidental save has been undone, and the file is present as untracked content again. As before, this action has not been recorded in your history.
9.3.4. Viewing previous versions of files and datasets¶
The next question is truly magical: How does one see data as it was at a previous state in history?
This magic trick can be performed with the git checkout (manual).
It is a very heavily used command for various tasks, but among
many it can send you back in time to view the state of a dataset
at the time of a specific commit.
Let’s say you want to find out which notes you took in the first few chapters of the handbook. Find a commit shasum in your history to specify the point in time you want to go back to:
$ git log -n 16 --oneline
f7863f3 save my favorite Git joke
23072dd remove obsolete subds
50359f3 [DATALAD] Added subdataset
f7a31cb save cropped logos to Git
c7f94fa move book back from midterm_project
d8a4aec move book into midterm_project
ba91786 add container and execute analysis within container
ebc300e finished my midterm project
efc0ab0 [DATALAD] Recorded changes
c403f14 add note on DataLad's procedures
39c928e add note on configurations and git config
4beb2bc Add note on adding siblings
6343867 Merge remote-tracking branch 'roommate/main'
822bf54 add note about datalad update
191e2a3 Include nesting demo from datalad website
d664af1 add note on git annex whereis
Let’s go 15 commits back in time:
$ git checkout d0e83f29✂SHA1
warning: unable to rmdir 'midterm_project': Directory not empty
Note: switching to 'd0e83f29✂SHA1'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -c with the switch command. Example:
git switch -c <new-branch-name>
Or undo this operation with:
git switch -
Turn off this advice by setting config variable advice.detachedHead to false
HEAD is now at d0e83f2 add note about cloning from paths and recursive datalad get
How did your notes.txt file look at this point?
$ tail notes.txt
registered in the superdataset -- you will have to do a
"datalad get -n PATH/TO/SUBDATASET" to install the subdataset for file
availability meta data. The -n/--no-data option prevents that file
contents are also downloaded.
Note that a recursive "datalad get" would install all further
registered subdatasets underneath a subdataset, so a safer way to
proceed is to set a decent --recursion-limit:
"datalad get -n -r --recursion-limit 2 <subds>"
Neat, isn’t it? By checking out a commit shasum you can explore a previous
state of a datasets history. And this does not only apply to simple text
files, but every type of file in your dataset, regardless of size.
The checkout command however led to something that Git calls a “detached HEAD state”.
While this sounds scary, a git checkout main will bring you
back into the most recent version of your dataset and get you out of the
“detached HEAD state”:
$ git checkout main
Previous HEAD position was d0e83f2 add note about cloning from paths and recursive datalad get
Switched to branch 'main'
Note one very important thing: The previously untracked files are still there.
$ datalad status
untracked: Gitjoke1.txt (file)
untracked: Gitjoke3.txt (file)
untracked: apdffile.pdf (file)
The contents of notes.txt will now be the most recent version again:
$ tail notes.txt
configurations, create files or file hierarchies, or perform arbitrary
tasks in datasets. They can be shipped with DataLad, its extensions,
or datasets, and you can even write your own procedures and distribute
them.
The "datalad run-procedure" command is used to apply such a procedure
to a dataset. Procedures shipped with DataLad or its extensions
starting with a "cfg" prefix can also be applied at the creation of a
dataset with "datalad create -c <PROC-NAME> <PATH>" (omitting the
"cfg" prefix).
… Wow! You traveled back and forth in time!
But an even more magical way to see the contents of files in previous
versions is Git’s cat-file command: Among many other things, it lets
you read a file’s contents as of any point in time in the history, without a
prior git checkout (note that the output is shortened for brevity and shows only the last few lines of the file):
$ git cat-file --textconv d0e83f29✂SHA1:notes.txt
Note that subdatasets will not be installed by default, but are only
registered in the superdataset -- you will have to do a
"datalad get -n PATH/TO/SUBDATASET" to install the subdataset for file
availability meta data. The -n/--no-data option prevents that file
contents are also downloaded.
Note that a recursive "datalad get" would install all further
registered subdatasets underneath a subdataset, so a safer way to
proceed is to set a decent --recursion-limit:
"datalad get -n -r --recursion-limit 2 <subds>"
The cat-file command is very versatile, and it’s documentation will list all of its functionality. To use it to see the contents of a file at a previous state as done above, this is how the general structure looks like:
$ git cat-file --textconv SHASUM:<path/to/file>
9.3.5. Undoing latest modifications of files¶
Previously, we saw how to remove files from a datasets history that were accidentally saved and thus tracked for the first time. How does one undo a modification to a tracked file?
Let’s modify the saved Gitjoke1.txt:
$ echo "this is by far my favorite joke!" >> Gitjoke2.txt
$ cat Gitjoke2.txt
Knock knock. Who's there? Git.
Git-who?
Sorry, 'who' is not a git command - did you mean 'show'?
this is by far my favorite joke!
$ datalad status
untracked: Gitjoke1.txt (file)
untracked: Gitjoke3.txt (file)
untracked: apdffile.pdf (file)
modified: Gitjoke2.txt (file)
$ datalad save -m "add joke evaluation to joke" Gitjoke2.txt
add(ok): Gitjoke2.txt (file)
save(ok): . (dataset)
How could this modification to Gitjoke2.txt be undone?
With the git reset command again. If you want to
“unsave” the modification but keep it in the file, use
git reset --mixed as before. However, if you want to
get rid of the modifications entirely, use the option --hard
instead of --mixed:
$ git log -n 2 --oneline
54e0e77 add joke evaluation to joke
f7863f3 save my favorite Git joke
$ git reset --hard f7863f37✂SHA1
HEAD is now at f7863f3 save my favorite Git joke
$ cat Gitjoke2.txt
Knock knock. Who's there? Git.
Git-who?
Sorry, 'who' is not a git command - did you mean 'show'?
The change has been undone completely. This method will work with files stored in Git and annexed files.
Note that this operation only restores this one file, because the commit that was undone only contained modifications to this one file. This is a demonstration of one of the reasons why one should strive for commits to represent meaningful logical units of change – if necessary, they can be undone easily.
9.3.6. Undoing past modifications of files¶
What git reset did was to undo commits from
the most recent version of your dataset. How
would one undo a change that happened a while ago, though,
with important changes being added afterwards that you want
to keep?
Let’s save a bad modification to Gitjoke2.txt,
but also a modification to notes.txt:
$ echo "bad modification" >> Gitjoke2.txt
$ datalad save -m "did a bad modification" Gitjoke2.txt
add(ok): Gitjoke2.txt (file)
save(ok): . (dataset)
$ cat << EOT >> notes.txt
Git has many handy tools to go back in forth in time and work with the
history of datasets. Among many other things you can rewrite commit
messages, undo changes, or look at previous versions of datasets.
A superb resource to find out more about this and practice such Git
operations is this chapter in the Pro-git book:
https://git-scm.com/book/en/v2/Git-Tools-Rewriting-History
EOT
$ datalad save -m "add note on helpful git resource" notes.txt
add(ok): notes.txt (file)
save(ok): . (dataset)
The objective is to remove the first, “bad” modification, but
keep the more recent modification of notes.txt. A git reset
command is not convenient, because resetting would need to reset
the most recent, “good” modification as well.
One way to accomplish it is with an interactive rebase, using the
git rebase -i (manual) command[5]. Experienced Git-users will know
under which situations and how to perform such an interactive rebase.
However, outlining an interactive rebase here in the handbook could lead to problems for readers without (much) Git experience: An interactive rebase, even if performed successfully, can lead to many problems if it is applied with too little experience, for example, in any collaborative real-world project.
Instead, we demonstrate a different, less intrusive way to revert one or more
changes at any point in the history of a dataset: the git revert (manual)
command.
Instead of rewriting the history, it will add an additional commit in which
the changes of an unwanted commit are reverted.
The command looks like this:
$ git revert SHASUM
where SHASUM specifies the commit hash of the modification that should
be reverted.
Reverting more than a single commit
You can also specify a range of commits like this:
$ git revert OLDER_SHASUM..NEWERSHASUM
This command will revert all commits starting with the one after
OLDER_SHASUM (i.e. not including this commit) until and including
the one specified with NEWERSHASUM.
For each reverted commit, one new commit will be added to the history that
reverts it. Thus, if you revert a range of three commits, there will be three
reversal commits. If you however want the reversal of a range of commits
saved in a single commit, supply the --no-commit option as in
$ git revert --no-commit OLDER_SHASUM..NEWERSHASUM
After running this command, run a single git commit to conclude the
reversal and save it in a single commit.
Let’s see how it looks like:
$ git revert ed212010✂SHA1
[main 7dd7551] Revert "did a bad modification"
Date: Tue Jun 18 16:13:00 2019 +0000
1 file changed, 1 deletion(-)
This is the state of the file in which we reverted a modification:
$ cat Gitjoke2.txt
Knock knock. Who's there? Git.
Git-who?
Sorry, 'who' is not a git command - did you mean 'show'?
It does not contain the bad modification anymore. And this is what happened in the history of the dataset:
$ git log -n 3
commit 7dd7551d✂SHA1
Author: Elena Piscopia <elena@example.net>
Date: Tue Jun 18 16:13:00 2019 +0000
Revert "did a bad modification"
This reverts commit ed212010✂SHA1.
commit 36c4b840✂SHA1
Author: Elena Piscopia <elena@example.net>
Date: Tue Jun 18 16:13:00 2019 +0000
add note on helpful git resource
commit ed212010✂SHA1
Author: Elena Piscopia <elena@example.net>
Date: Tue Jun 18 16:13:00 2019 +0000
did a bad modification
The commit that introduced the bad modification is still present, but it
transparently gets undone with the most recent commit. At the same time, the
good modification of notes.txt was not influenced in any way. The
git revert command is thus a transparent and safe way of undoing past
changes. Note though that this command can only be used efficiently if the
commits in your datasets history are meaningful, independent units – having
several unrelated modifications in a single commit may make an easy solution
with git revert impossible and instead require a complex
checkout, revert, or rebase operation.
Finally, let’s take a look at the state of the dataset after this operation:
$ datalad status
untracked: Gitjoke1.txt (file)
untracked: Gitjoke3.txt (file)
untracked: apdffile.pdf (file)
As you can see, unsurprisingly, the git revert command had no
effects on anything else but the specified commit, and previously untracked
files are still present.
9.3.7. Oh no! I’m in a merge conflict!¶
When working with the history of a dataset, especially when rewriting the history with an interactive rebase or when reverting commits, it is possible to run into so-called merge conflicts. Merge conflicts happen when Git needs assistance in deciding which changes to keep and which to apply. It will require you to edit the file the merge conflict is happening in with a text editor, but such merge conflict are by far not as scary as they may seem during the first few times of solving merge conflicts.
This section is not a guide on how to solve merge-conflicts, but a broad overview on the necessary steps, and a pointer to a more comprehensive guide.
The first thing to do if you end up in a merge conflict is to read the instructions Git is giving you – they are a useful guide.
Also, it is reassuring to remember that you can always get out of a merge conflict by aborting the operation that led to it (e.g.,
git rebase --abort).To actually solve a merge conflict, you will have to edit files: In the documents the merge conflict applies to, Git marks the sections it needs help with with markers that consists of
>,<, and=signs and commit shasums or branch names. There will be two marked parts, and you have to delete the one you do not want to keep, as well as all markers.Afterwards, run
git add <path/to/file>and finally agit commit.
GitHub has an excellent resource on how to deal with merge conflicts.
9.3.8. Summary¶
This guest lecture has given you a glimpse into how to work with the
history of your DataLad datasets.
To conclude this section, let’s remove all untracked contents from
the dataset. This can be done with git clean (manual): The command
git clean -f swipes your dataset clean and removes any untracked
file.
Careful! This is not revertible, and content lost with this commands cannot be recovered!
If you want to be extra sure, run git clean -fn beforehand – this will
give you a list of the files that would be deleted.
$ git clean -f
Removing Gitjoke1.txt
Removing Gitjoke3.txt
Removing apdffile.pdf
Afterwards, the datalad status returns nothing, indicating a
clean dataset state with no untracked files or modifications.
$ datalad status
nothing to save, working tree clean
Finally, if you want, apply your new knowledge about reverting commits
to remove the Gitjoke2.txt file.
Footnotes