8.2. Publishing datasets to Git repository hosting¶
Because DataLad datasets are Git repositories, it is possible to
datalad push (manual) datasets to any Git repository hosting service, such as
GitHub, GitLab, GIN, Bitbucket, Gogs, or Gitea.
These published datasets are ordinary siblings of your dataset, and among other advantages, they can constitute a back-up, an entry-point to retrieve your dataset for others or yourself, the backbone for collaboration on datasets, or the means to enhance visibility, findability and citeability of your work[1].
This section contains a brief overview on how to publish your dataset to different services.
8.2.1. Git repository hosting and annexed data¶
As outlined in a number of sections before, Git repository hosting sites typically do not support dataset annexes - some, like GIN however, do.
Depending on whether or not an annex is supported, you can push either only your Git history to the sibling, or the complete dataset including annexed file contents.
You can find out whether a sibling on a remote hosting services carries an annex or not by running the datalad siblings (manual) command.
A +, -, or ? sign in parenthesis indicates whether the sibling carries an annex, does not carry an annex, or whether this information isn’t yet known.
In the example below you can see that the public GitHub repository github.com/psychoinformatics-de/studyforrest-data-phase2 does not carry an annex on GitHub (the sibling origin), but that the annexed data are served from an additional sibling mddatasrc (a special remote with annex support).
Even though the dataset sibling on GitHub does not serve the data, it constitutes a simple, findable access point to retrieve the dataset, and can be used to provide updates and fixes via pull requests, issues, etc.
$ # a clone of github/psychoinformatics/studyforrest-data-phase2 has the following siblings:
$ datalad siblings
.: here(+) [git]
.: mddatasrc(+) [https://datapub.fz-juelich.de/studyforrest/studyforrest/phase2/.git (git)]
.: origin(-) [git@github.com:psychoinformatics-de/studyforrest-data-phase2.git (git)]
There are multiple ways to create a dataset sibling on a repository hosting site to push your dataset to.
8.2.2. How to add a sibling on a Git repository hosting site: The manual way¶
Create a new repository via the webinterface of the hosting service of your choice. The screenshots in Fig. 8.7 and Fig. 8.8 show examples of this. The new repository does not need to have the same name as your local dataset, but it helps to associate local dataset and remote siblings.
Afterwards, copy the SSH or HTTPS URL of the repository. Usually, repository hosting services will provide you with a convenient way to copy it to your clipboard. An SSH URL takes the form
git@<hosting-service>:/<user>/<repo-name>.gitand an HTTPS URL takes the formhttps://<hosting-service>/<user>/<repo-name>.git. The type of URL you choose determines whether and how you will be able topushto your repository. Note that many services will require you to use the SSH URL to your repository in order to dodatalad pushoperations, so make sure to take the SSH and not the HTTPS URL if this is the case.If you pick the SSH URL, make sure to have an SSH key set up. This usually requires generating an SSH key pair if you do not have one yet, and uploading the public key to the repository hosting service. The Find-out-more on SSH keys points to a useful tutorial for this.
Use the URL to add the repository as a sibling. There are two commands that allow you to do that; both require that you give the sibling a name of your choice (common name choices are
upstream, or a short-cut for your user name or the hosting platform, but it’s completely up to you to decide):git remote add <name> <url>datalad siblings add --dataset . --name <name> --url <url>
Push your dataset to the new sibling:
datalad push --to <name>
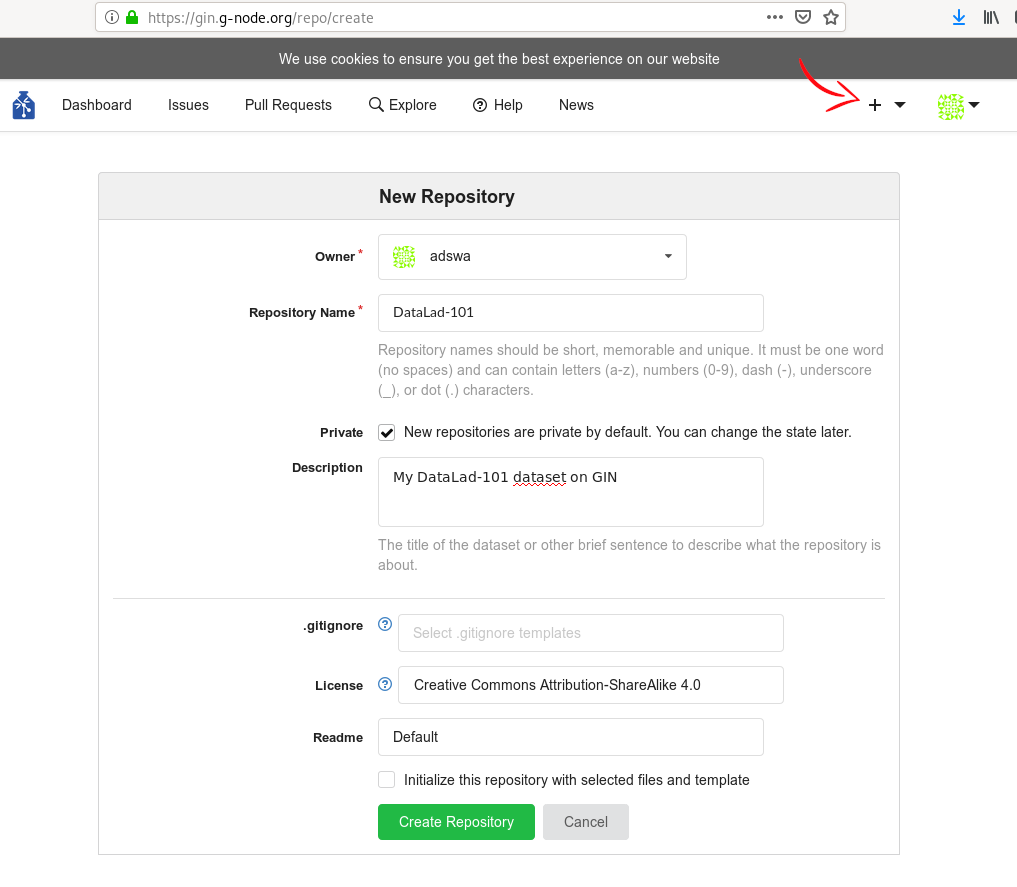
Fig. 8.7 Webinterface of GIN during the creation of a new repository.¶
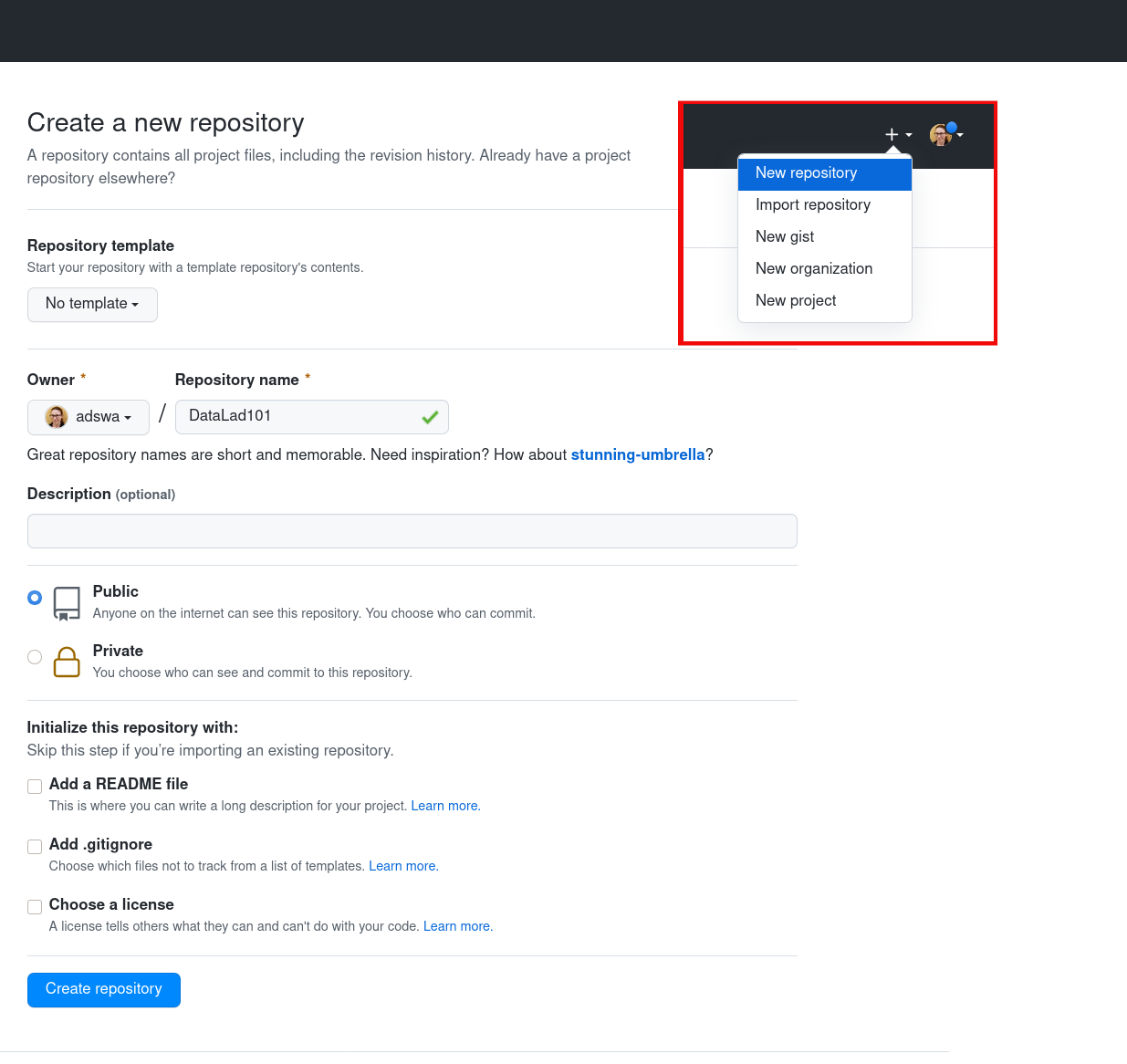
Fig. 8.8 Webinterface of GitHub during the creation of a new repository.¶
What is an SSH key and how can I create one?
An SSH key is an access credential in the SSH protocol that can be used to login from one system to remote servers and services, such as from your private computer to an SSH server. For repository hosting services such as GIN, GitHub, or GitLab, it can be used to connect and authenticate without supplying your username or password for each action.
A tutorial by GitHub at docs.github.com/en/github/authenticating-to-github/connecting-to-github-with-ssh
has a detailed step-by-step instruction to generate and use SSH keys for authentication.
You will also learn how add your public SSH key to your hosting service account
so that you can install or clone datasets or Git repositories via SSH (in addition
to the http protocol).
Don’t be intimidated if you have never done this before – it is fast and easy:
First, you need to create a private and a public key (an SSH key pair).
All this takes is a single command in the terminal. The resulting files are
text files that look like someone spilled alphabet soup in them, but constitute
a secure password procedure.
You keep the private key on your own machine (the system you are connecting from,
and that only you have access to),
and copy the public key to the system or service you are connecting to.
On the remote system or service, you make the public key an authorized key to
allow authentication via the SSH key pair instead of your password. This
either takes a single command in the terminal, or a few clicks in a web interface
to achieve.
You should protect your SSH keys on your machine with a passphrase to prevent
others – e.g., in case of theft – to log in to servers or services with
SSH authentication[2], and configure an ssh agent
to handle this passphrase for you with a single command. How to do all of this
is detailed in the tutorial.
8.2.3. How to add a sibling on a Git repository hosting site: The automated way¶
DataLad provides create-sibling-* commands to automatically create datasets on certain hosting sites.
You can automatically create new repositories from the command line for GitHub, GitLab, GIN, Gogs, or Gitea.
This is implemented with a set of commands called datalad create-sibling-github (manual), datalad create-sibling-gitlab (manual), datalad create-sibling-gin (manual), datalad create-sibling-gogs (manual), and datalad create-sibling-gitea (manual).
Each command is slightly tuned towards the peculiarities of each particular platform, but the most important common parameters are streamlined across commands as follows:
[REPONAME](required): The name of the repository on the hosting site. It will be created under a user’s namespace, unless this argument includes an organization name prefix. For example,datalad create-sibling-github my-awesome-repowill create a new repository undergithub.com/<user>/my-awesome-repo, whiledatalad create-sibling-github <orgname>/my-awesome-repowill create a new repository of this name under the GitHub organization<orgname>(given appropriate permissions).-s/--name <name>(required): A name under which the sibling is identified. By default, it will be based on or similar to the hosting site. For example, the sibling created withdatalad create-sibling-githubwill be calledgithubby default.--credential <name>(optional): Credentials used for authentication are stored internally by DataLad under specific names. These names allow you to have multiple credentials, and flexibly decide which one to use. When--credential <name>is the name of an existing credential, DataLad tries to authenticate with the specified credential; when it does not yet exist DataLad will prompt interactively for a credential, such as an access token, and store it under the given<name>for future authentications. By default, DataLad will name a credential according to the hosting service URL it used for, such asdatalad-api.github.comas the default for credentials used to authenticate against GitHub.--access-protocol {https|ssh|https-ssh}(defaulthttps): Whether to use SSH or HTTPS URLs, or a hybrid version in which HTTPS is used to pull and SSH is used to push. Using SSH URLs requires an SSH key setup, but is a very convenient authentication method, especially when pushing updates – which would need manual input on user name and token with everypushover HTTPS.--dry-run(optional): With this flag set, the command will not actually create the target repository, but only perform tests for name collisions and report repository name(s).--private(optional): A switch that, if set, makes sure that the created repository is private.
Other streamlined arguments, such as --recursive or --publish-depends allow you to perform more complex configurations, such as publication of dataset hierarchies or connections to special remotes. Upcoming walk-throughs will demonstrate them.
Self-hosted repository services, e.g., Gogs or Gitea instances, have an additional required argument, the --api flag.
It needs to point to the URL of the instance, for example
$ datalad create-sibling-gogs my_repo_on_gogs --api "https://try.gogs.io"
GitLab’s internal organization differs from that of the other hosting services, and as there are multiple different GitLab instances, create-sibling-gitlab requires slightly more configuration than the other commands.
Thus, a short walk-through is at the end of this section.
8.2.4. Authentication by token¶
To create or update repositories on remote hosting services you will need to set up appropriate authentication and permissions. In most cases, this will be in the form of an authorization token with a specific permission scope.
8.2.4.1. What is a token?¶
Personal access tokens are an alternative to authenticating via your password, and take the form of a long character string, associated with a human-readable name or description.
If you are prompted for username and password in the command line, you would enter your token in place of the password[3].
Note that you do not have to type your token at every authentication – your token will be stored on your system the first time you have used it and automatically reused whenever relevant.
How does the authentication storage work?
Passwords, user names, tokens, or any other login information is stored in your system’s (encrypted) keyring. It is a built-in credential store, used in all major operating systems, and can store credentials securely.
You can have multiple tokens, and each of them can get a different scope of permissions, but it is important to treat your tokens like passwords and keep them secret.
8.2.4.2. Which permissions do they need?¶
The most convenient way to generate tokens is typically via the webinterface of the hosting service of your choice. Often, you can specifically select which set of permissions a specific token has in a drop-down menu similar (but likely not identical) to the screenshot from GitHub in Fig. 8.9.
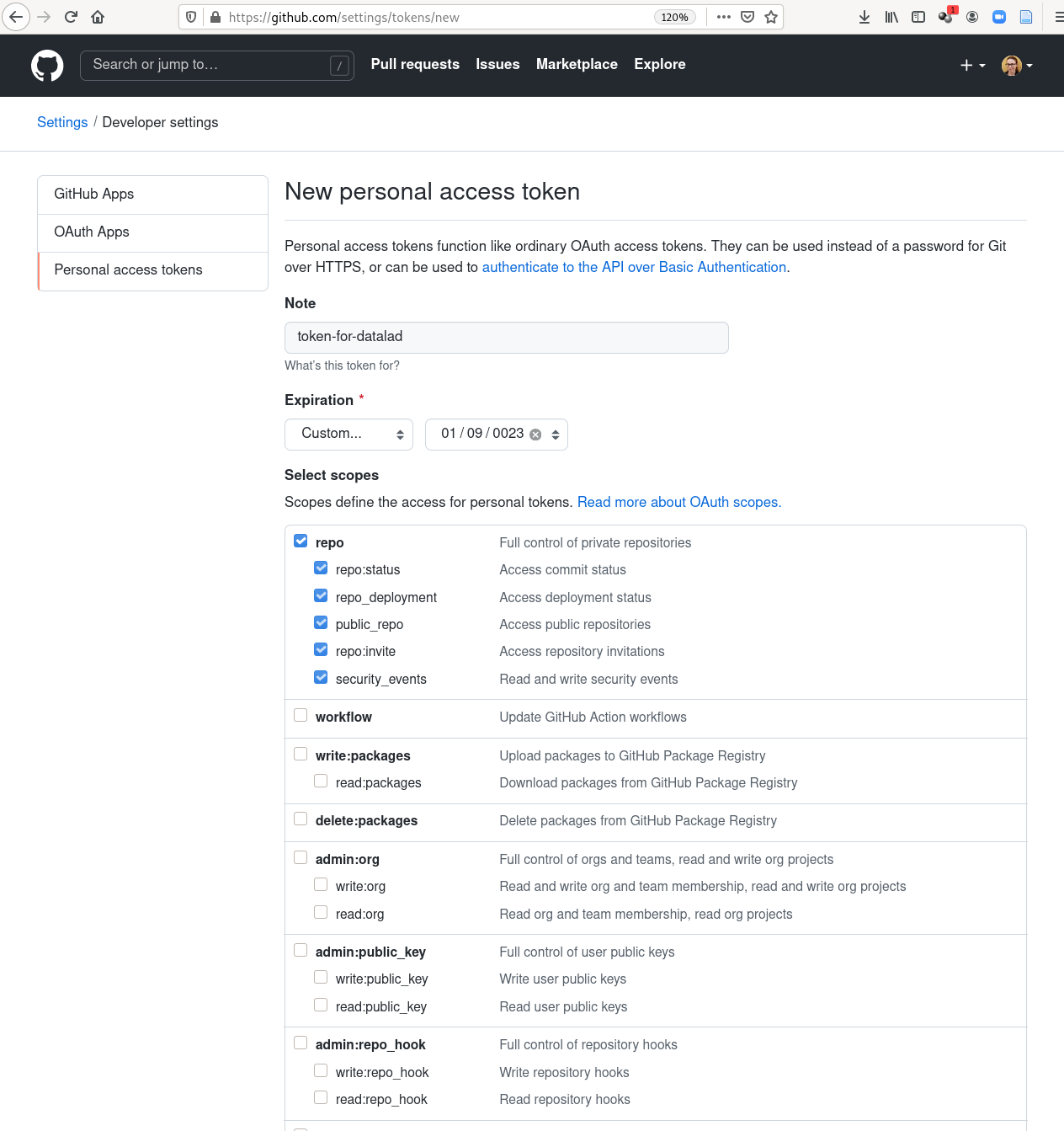
Fig. 8.9 Webinterface to generate an authentication token on GitHub. One typically has to set a name and permission set, and potentially an expiration date.¶
For creating and updating repositories with DataLad commands it is usually sufficient to grant only repository-related permissions. However, broader permission sets may also make sense. Should you employ GitHub workflows, for example, a token without “workflow” scope could not push changes to workflow files, resulting in errors like this one:
[remote rejected] (refusing to allow a Personal Access Token to create or update workflow `.github/workflows/benchmarks.yml` without `workflow` scope)]
8.2.5. Creating a sibling on GitLab¶
GitLab is an open source Git repository hosting platform, and many institutions and companies deploy their own instance. This short walk-through demonstrates the necessary steps to create a GitLab sibling, and the different options GitLab allows for when creating siblings recursively for a dataset hierarchy.
8.2.5.1. Step 1: Configure your site¶
As a first step, users will need to create a configuration file following the format of python-gitlab.
This configuration file is typically called .python-gitlab.cfg and placed into a users home directory.
It contains one section per GitLab instance, and a [global] section that defines the default instance to use.
Here is an example:
$ cat ~/.python-gitlab.cfg
[global]
default = my-university-gitlab
ssl_verify = true
timeout = 5
[my-university-gitlab]
url = https://gitlab.my-university.com
private_token = <here-is-your-token>
api_version = 4
[gitlab-general]
url = https://gitlab.com
api_version = 4
private_token = <here-is-your-token>
Once this configuration is in place, create-sibling-gitlab’s --site parameter can be supplied with the name of the instance you want to use (e.g., datalad create-sibling-gitlab --site gitlab-general).
Ensure that the token for each instance has appropriate permissions to create new groups and projects under your user account using the GitLab API in Fig. 8.10.
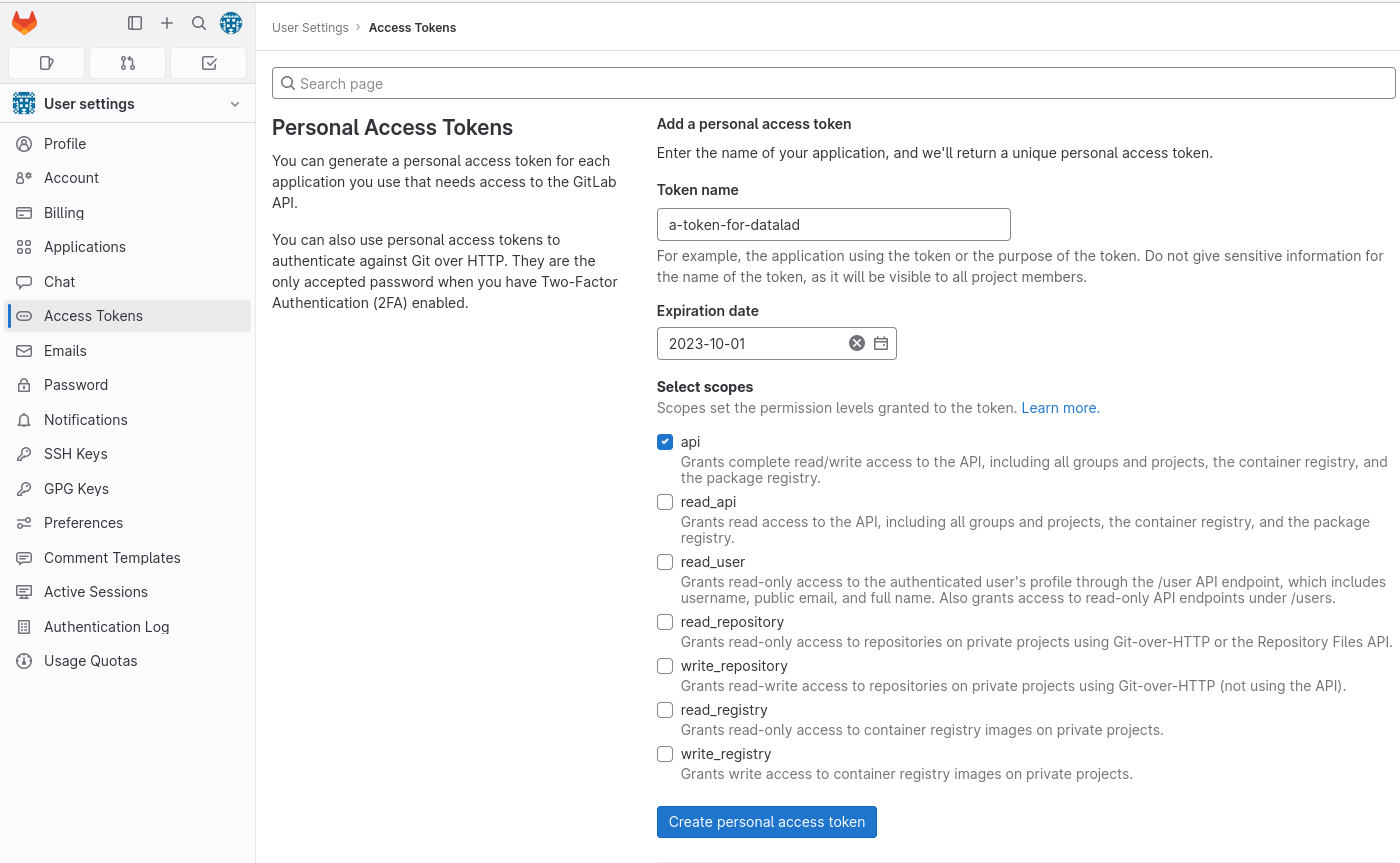
Fig. 8.10 Webinterface to generate an authentication token on GitLab. One typically has to set a name and permission set, and potentially an expiration date.¶
8.2.5.2. Step 2: Create or select a group¶
GitLab’s organization consists of projects and groups.
Projects are single repositories, and groups can be used to manage one or more projects at the same time.
In order to use create-sibling-gitlab, a user must create a group via the web interface, or specify a pre-existing group, because GitLab does not allow root-level groups to be created via their API.
Only when there already is a “parent” group DataLad and other tools can create sub-groups and projects automatically.
In the screenshots Fig. 8.11 and Fig. 8.12, a new group my-datalad-root-level-group is created right underneath the user account.
The group name as shown in the URL bar is what DataLad needs in order to create sibling datasets.
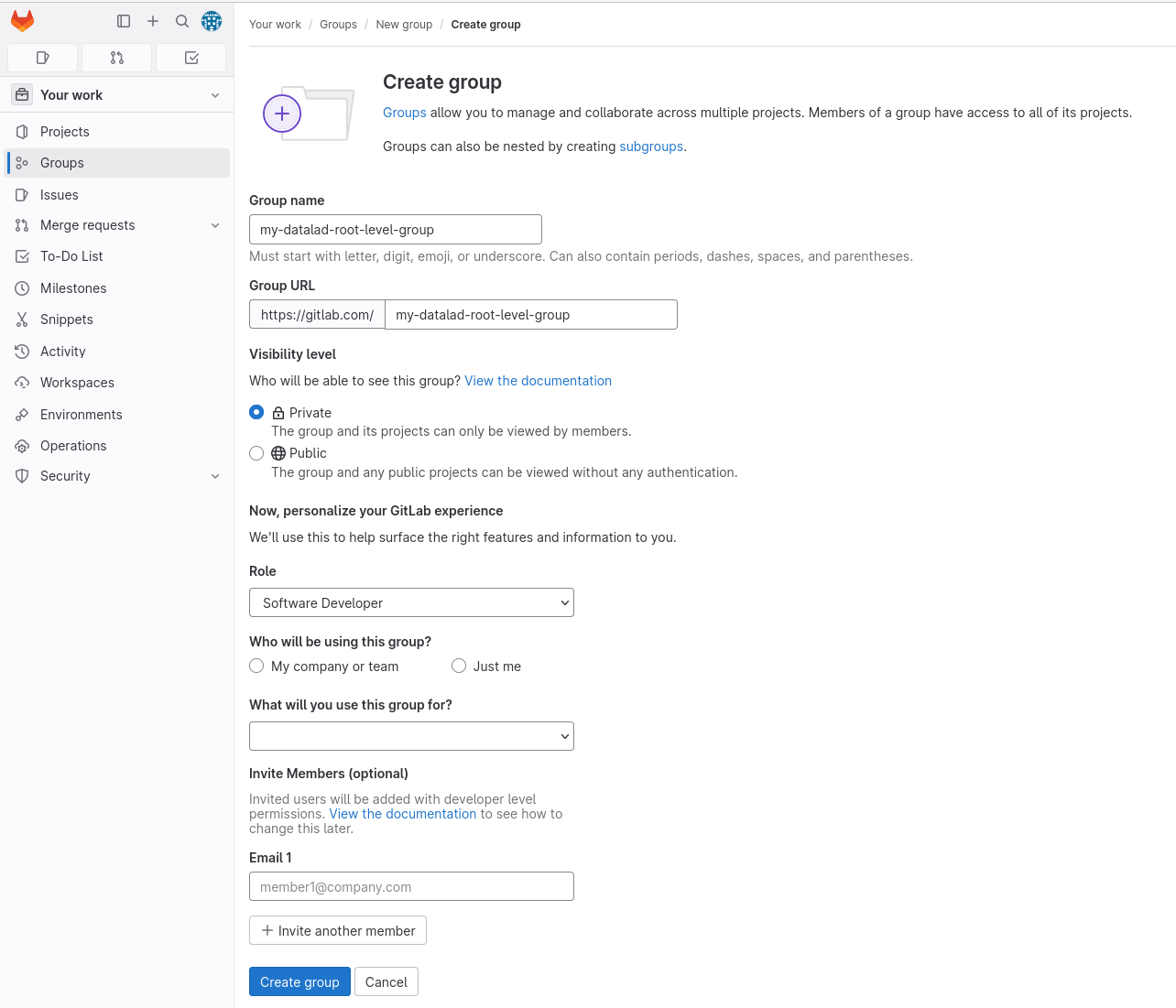
Fig. 8.11 Webinterface to create a root-level group on GitLab.¶
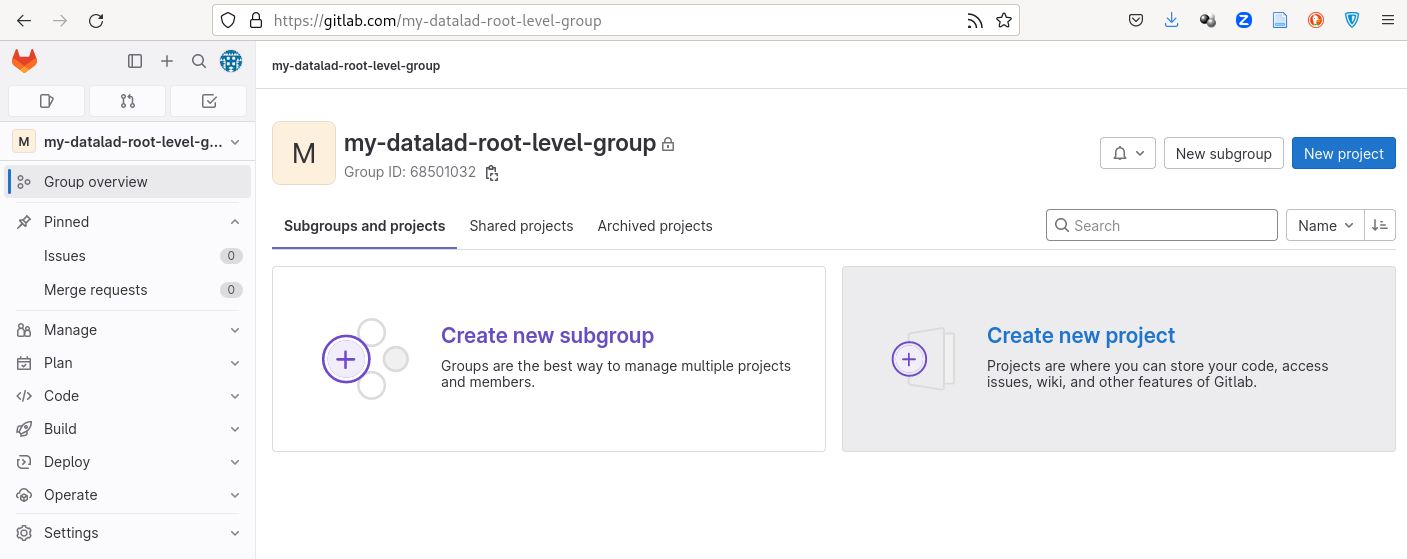
Fig. 8.12 A created root-level group in GitLab’s webinterface.¶
8.2.5.3. Step 3: Select a layout¶
Due to the distinction between groups and projects, GitLab allows two different layouts that DataLad can use to publish datasets or dataset hierarchies:
flat: All datasets become projects in the same, pre-existing group. The name of a project is its relative path within the root dataset, with all path separator characters replaced by ‘-’[4].
collection: A new group is created for the dataset. The root dataset (the topmost superdataset) is placed in a “project” project inside this group, and all nested subdatasets are represented inside the group using a “flat” layout[4]. This layout is the default.
Consider the DataLad-101 dataset, a superdataset with a several subdatasets in the following layout:
/home/me/dl-101/DataLad-101 # dataset
├── books/
│ └── [...]
├── code/
│ └── [...]
├── midterm_project/ # subdataset
│ ├── code/
│ └── [...]
│ └── input/ # sub-subdataset
├── recordings/
│ └── longnow/ # subdataset
│ ├── [...]
How the collection and flat layouts for this dataset look in practice is shown in Fig. 8.13.
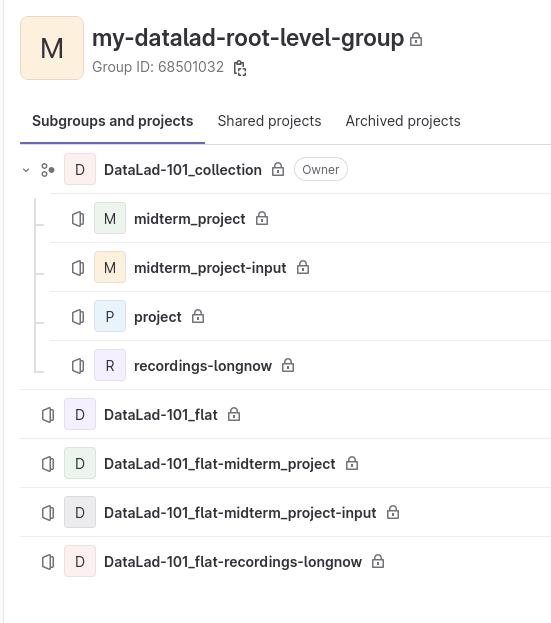
Fig. 8.13 The collection layout has a group (DataLad-101_collection, defined by the user with a configuration) with four projects underneath. The project project contains the root-level dataset, and all contained subdatasets are named according to their location in the dataset. The flat layout consists of projects in the root-level group. The project name for the superdataset (DataLad-101_flat) is defined by the user with a configuration, and the names of the subdatasets extend this project name based on their location in the dataset hierarchy.¶
8.2.5.4. Publishing a single dataset¶
When publishing a single dataset, users can configure the project or group name as a command argument --project.
Here are two command examples and their outcomes.
For a flat layout, the --project parameter determines the project name, shown in Fig. 8.14.
$ datalad create-sibling-gitlab --site gitlab-general --layout flat --project my-datalad-root-level-group/this-will-be-the-project-name
create_sibling_gitlab(ok): . (dataset) [sibling repository 'gitlab' created at https://gitlab.com/my-datalad-root-level-group/this-will-be-the-project-name]
configure-sibling(ok): . (sibling)
action summary:
configure-sibling (ok: 1)
create_sibling_gitlab (ok: 1)
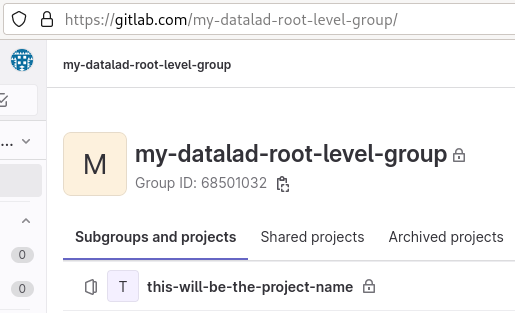
Fig. 8.14 An example dataset using GitLab’s “flat” layout.¶
For a collection layout, the --project parameter determines the group name, shown in figure Fig. 8.15.
$ datalad create-sibling-gitlab --site gitlab-general --layout collection --project my-datalad-root-level-group/this-will-be-the-group-name
create_sibling_gitlab(ok): . (dataset) [sibling repository 'gitlab' created at https://gitlab.com/my-datalad-root-level-group/this-will-be-the-group-name/project]
configure-sibling(ok): . (sibling)
action summary:
configure-sibling (ok: 1)
create_sibling_gitlab (ok: 1)
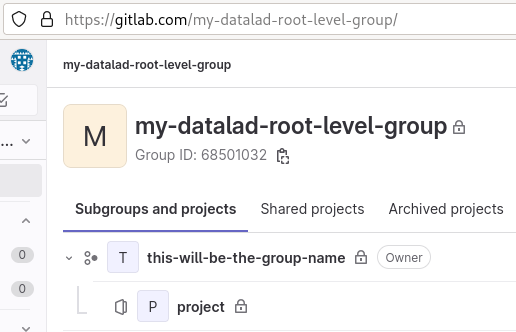
Fig. 8.15 An example dataset using GitLab’s “collection” layout.¶
8.2.5.5. Publishing datasets recursively¶
When publishing a series of datasets recursively, the --project argument cannot be used anymore - otherwise, all datasets in the hierarchy would attempt to create the same group or project over and over again.
Instead, one configures the root level dataset, and the names for underlying datasets will be derived from this configuration:
$ # do the configuration for the top-most dataset
$ # either configure with Git
$ git config --local --replace-all \
datalad.gitlab-<gitlab-site>-project \
'my-datalad-root-level-group/DataLad-101_flat'
$ # or configure with DataLad
$ datalad configuration set \
datalad.gitlab-<gitlab-site>-project='my-datalad-root-level-group/DataLad-101_flat'
Afterwards, publish dataset hierarchies with the --recursive flag:
$ datalad create-sibling-gitlab --site gitlab-general --recursive --layout flat
create_sibling_gitlab(ok): . (dataset) [sibling repository 'gitlab' created at https://gitlab.com/my-datalad-root-level-group/DataLad-101_flat]
configure-sibling(ok): . (sibling)
create_sibling_gitlab(ok): midterm_project (dataset) [sibling repository 'gitlab' created at https://gitlab.com/my-datalad-root-level-group/DataLad-101_flat-midterm_project]
configure-sibling(ok): . (sibling)
create_sibling_gitlab(ok): midterm_project/input (dataset) [sibling repository 'gitlab' created at https://gitlab.com/my-datalad-root-level-group/DataLad-101_flat-midterm_project-input]
configure-sibling(ok): . (sibling)
create_sibling_gitlab(ok): recordings/longnow (dataset) [sibling repository 'gitlab' created at https://gitlab.com/my-datalad-root-level-group/DataLad-101_flat-recordings-longnow]
configure-sibling(ok): . (sibling)
action summary:
configure-sibling (ok: 4)
create_sibling_gitlab (ok: 4)
8.2.5.6. Final step: Pushing to GitLab¶
Once you have set up your dataset sibling(s), you can push individual datasets with datalad push --to gitlab or push recursively across a hierarchy by adding the --recursive flag to the push command.
Footnotes