8.4. Walk-through: Amazon S3 as a special remote¶
This walk-through requires git-annex >= 10.20230802
Prior versions of git-annex do not support public access via the publicurl parameter with S3 buckets created after April 2023.
Find out more about this in this discussion.
Amazon S3 (or Amazon Simple Storage Service) is a popular service by Amazon Web Services (AWS) that provides object storage through a web service interface. An S3 bucket can be configured as a git-annex special remote, allowing it to be used as a DataLad publication target. This means that you can use Amazon S3 to store your annexed data contents and allow users to install your full dataset with DataLad from a publicly available repository service such as GitHub.
In this section, we provide a walkthrough on how to set up Amazon S3 for hosting your DataLad dataset, and how to access this data locally from GitHub.
8.4.1. Prerequisites¶
In order to use Amazon S3 for hosting your datasets, and to follow the steps below, you need to:
Signup for an AWS account
Verify your account
Find your AWS access key
Signup for a GitHub account
Install wget in order to download sample data
Optional: install the AWS Command Line Interface
The AWS signup procedure requires you to provide your e-mail address, physical address, and credit card details before verification is possible.
AWS account usage can incur costs
While Amazon provides Free Tier access to its services, it can still potentially result in costs if usage exceeds Free Tier Limits. Be sure to take note of these limits, or set up automatic tracking alerts to be notified before incurring unnecessary costs.
To find your AWS access key, log in to the AWS Console, open the dropdown menu at your username (top right), and select “My Security Credentials”. A new page will open with several options, including “Access keys (access key ID and secret access key)” from where you can select “Create New Access Key” or access existing credentials. Take note to copy both the “Access Key ID” and “Secret Access Key”.
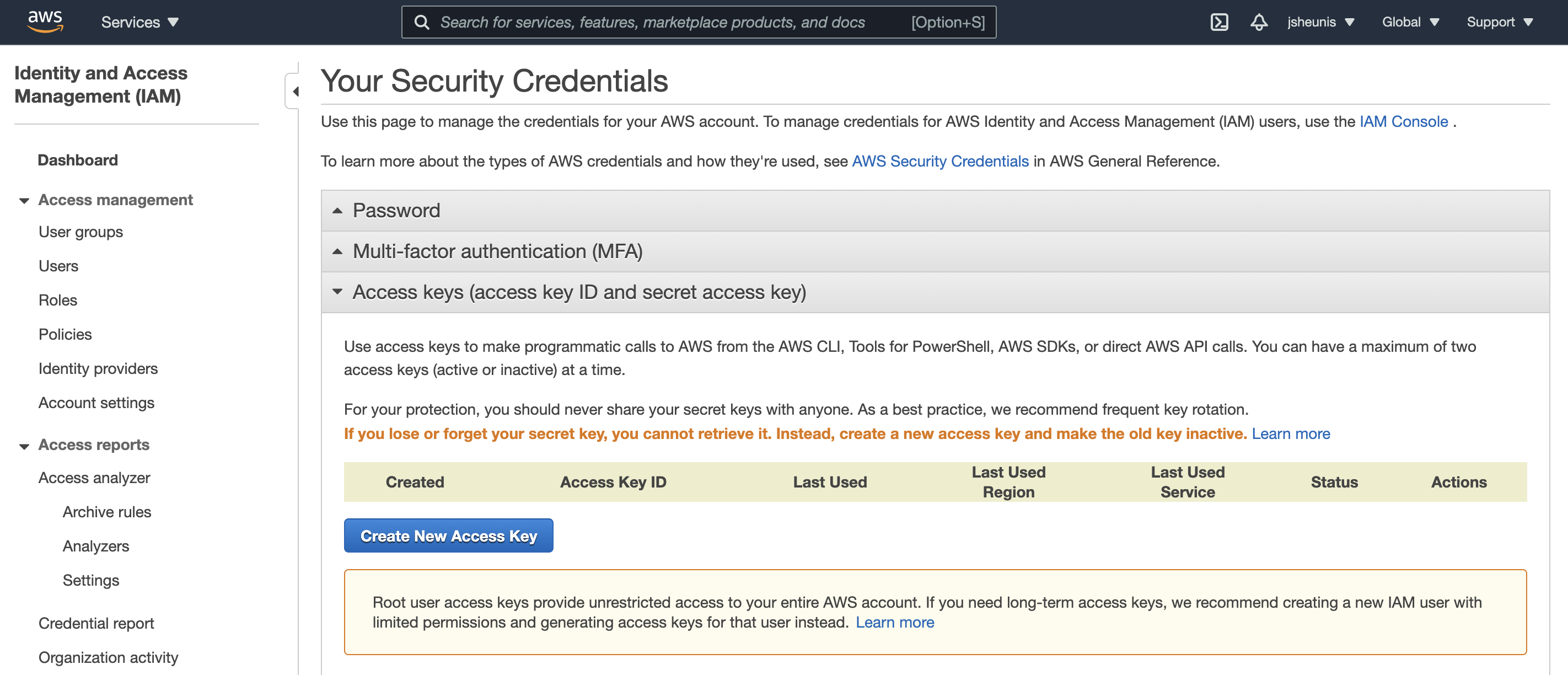
Fig. 8.16 Create a new AWS access key from “My Security Credentials”¶
To ensure that your access key details are known when initializing the special remote, export them as environment variables in your shell:
$ export AWS_ACCESS_KEY_ID="your-access-key-ID"
$ export AWS_SECRET_ACCESS_KEY="your-secret-access-key"
In order to work directly with AWS via your command-line shell, you can install the AWS CLI. However, that is not required for this walkthrough.
Lastly, to publish your data repository to GitHub, from which users will be able do install the complete dataset, you will need a GitHub account.
8.4.2. Your DataLad dataset¶
If you already have a small DataLad dataset to practice with, feel free to use it during the rest of the walkthrough. If you do not have data, no problem! As a general introduction, the steps below will download a small public neuroimaging dataset, and transform it into a DataLad dataset. We’ll use the MoAEpilot dataset containing anatomical and functional images from a single brain, as well as some metadata.
In the first step, we create a new directory called neuro-data-s3, we download and extract the data,
and then we move the extracted contents into our new directory:
$ cd <wherever-you-want-to-create-the-dataset>
$ mkdir neuro-data-s3 && \
wget https://www.fil.ion.ucl.ac.uk/spm/download/data/MoAEpilot/MoAEpilot.bids.zip -O neuro-data-s3.zip && \
unzip neuro-data-s3.zip -d neuro-data-s3 && \
rm neuro-data-s3.zip && \
cd neuro-data-s3 && \
mv MoAEpilot/* . && \
rm -R MoAEpilot
--2021-06-01 09:32:25-- https://www.fil.ion.ucl.ac.uk/spm/download/data/MoAEpilot/MoAEpilot.bids.zip
Resolving www.fil.ion.ucl.ac.uk (www.fil.ion.ucl.ac.uk)... 193.62.66.18
Connecting to www.fil.ion.ucl.ac.uk (www.fil.ion.ucl.ac.uk)|193.62.66.18|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 30176409 (29M) [application/zip]
Saving to: ‘neuro-data-s3.zip’
neuro-data-s3.zip 100%[=============================================================================================================================>] 28.78M 55.3MB/s in 0.5s
2021-06-01 09:32:25 (55.3 MB/s) - ‘neuro-data-s3.zip’ saved [30176409/30176409]
Archive: neuro-data-s3.zip
creating: neuro-data-s3/MoAEpilot/
inflating: neuro-data-s3/MoAEpilot/task-auditory_bold.json
inflating: neuro-data-s3/MoAEpilot/README
inflating: neuro-data-s3/MoAEpilot/dataset_description.json
inflating: neuro-data-s3/MoAEpilot/CHANGES
creating: neuro-data-s3/MoAEpilot/sub-01/
creating: neuro-data-s3/MoAEpilot/sub-01/func/
inflating: neuro-data-s3/MoAEpilot/sub-01/func/sub-01_task-auditory_events.tsv
inflating: neuro-data-s3/MoAEpilot/sub-01/func/sub-01_task-auditory_bold.nii
creating: neuro-data-s3/MoAEpilot/sub-01/anat/
inflating: neuro-data-s3/MoAEpilot/sub-01/anat/sub-01_T1w.nii
Now we can view the directory tree to see the dataset content:
$ tree
.
├── CHANGES
├── README
├── dataset_description.json
├── sub-01
│ ├── anat
│ │ └── sub-01_T1w.nii
│ └── func
│ ├── sub-01_task-auditory_bold.nii
│ └── sub-01_task-auditory_events.tsv
└── task-auditory_bold.json
The next step is to ensure that this is a valid DataLad dataset,
with main as the default branch.
We can turn our neuro-data-s3 directory into a DataLad dataset with the
datalad create --force (manual) command. After that, we save the dataset with datalad save (manual):
$ datalad create --force --description "neuro data to host on s3"
[INFO ] Creating a new annex repo at /Users/jsheunis/Documents/neuro-data-s3
[INFO ] Scanning for unlocked files (this may take some time)
create(ok): /Users/jsheunis/Documents/neuro-data-s3 (dataset)
$ datalad save -m "Add public data"
add(ok): CHANGES (file)
add(ok): README (file)
add(ok): dataset_description.json (file)
add(ok): sub-01/anat/sub-01_T1w.nii (file)
add(ok): sub-01/func/sub-01_task-auditory_bold.nii (file)
add(ok): sub-01/func/sub-01_task-auditory_events.tsv (file)
add(ok): task-auditory_bold.json (file)
save(ok): . (dataset)
action summary:
add (ok: 7)
save (ok: 1)
8.4.3. Initialize the S3 special remote¶
The steps below have been adapted from instructions provided on git-annex documentation. For more info on the S3 special remote, see the s3 special remote manpage <https://git-annex.branchable.com/special_remotes/S3>.
By initializing the special remote, what actually happens in the background
is that a sibling is added to the DataLad dataset. This can be verified
by running datalad siblings (manual) before and after initializing the special
remote. Before, the only “sibling” is the actual DataLad dataset:
$ datalad siblings
.: here(+) [git]
To initialize a public S3 bucket as a special remote, we run git annex initremote (manual)
with several options, for which git-annex documentation on S3
provides detailed information. Be sure to select a unique bucket name
that adheres to Amazon S3’s bucket naming rules.
You can declare the bucket name (in this example “sample-neurodata-public”) as a variable since
it will be used again later.
$ BUCKET=sample-neurodata-public
$ git annex initremote public-s3 type=S3 encryption=none \
bucket=$BUCKET datacenter=EU autoenable=true
initremote public-s3 (checking bucket...) (creating bucket in EU...) ok
(recording state in git...)
The options used in this example include:
public-s3: the name we select for our special remote, so that git-annex and DataLad can identify ittype=S3: the type of special remote (git-annex can work with many special remote types)encryption=none: no encryption (alternatively enableencryption=shared, meaning files will be encrypted on S3, and anyone with a clone of the git repository will be able to download and decrypt them)bucket=$BUCKET: the name of the bucket to be created on S3 (using the declared variable)datacenter=EU: specify where the data will be located; here we set “EU” which is EU/Ireland a.k.a.eu-west-1(defaults to “US” if not specified)autoenable=true: git-annex will attempt to enable the special remote when it is run in a new clone, implying that users won’t have to run extra steps when installing the dataset with DataLad
After git annex initremote has successfully initialized the special remote,
you can run datalad siblings to see that a sibling has been added:
$ datalad siblings
.: here(+) [git]
.: public-s3(+) [git]
You can also visit the S3 Console and navigate
to “Buckets” to see your newly created bucket. It should only have a single
annex-uuid file as content, since no actual file content has been pushed yet.
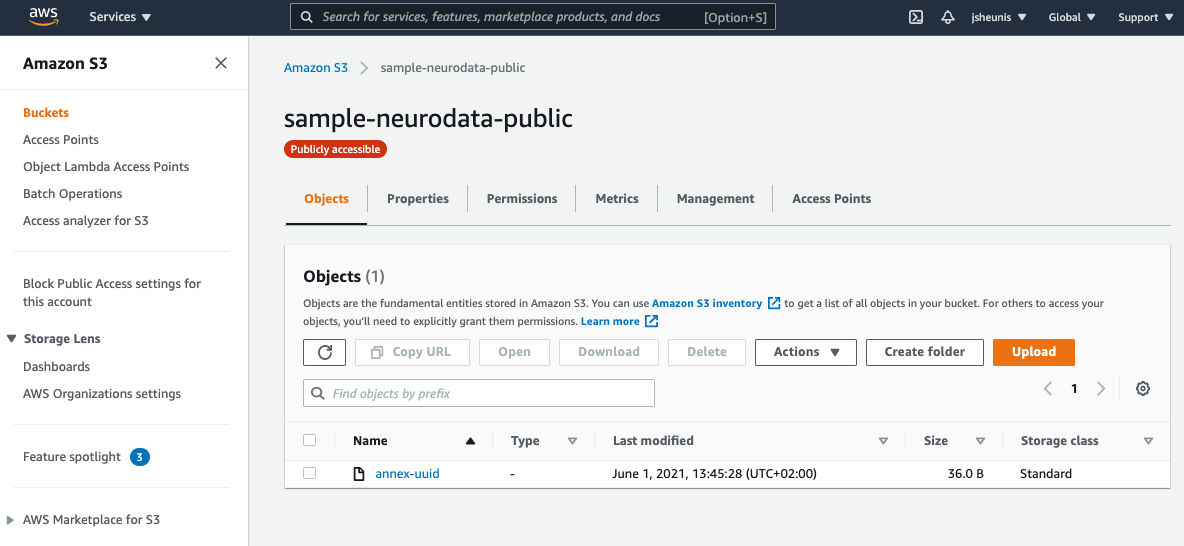
Fig. 8.17 A newly created public S3 bucket¶
By default, this bucket and its contents are not publicly accessible. To make them public, switch to the “Permissions” tab in your buckets S3 console overview, and turn the option “Block all public access” off (see Advanced examples - configure s3 via terraform for how to do this using terraform).
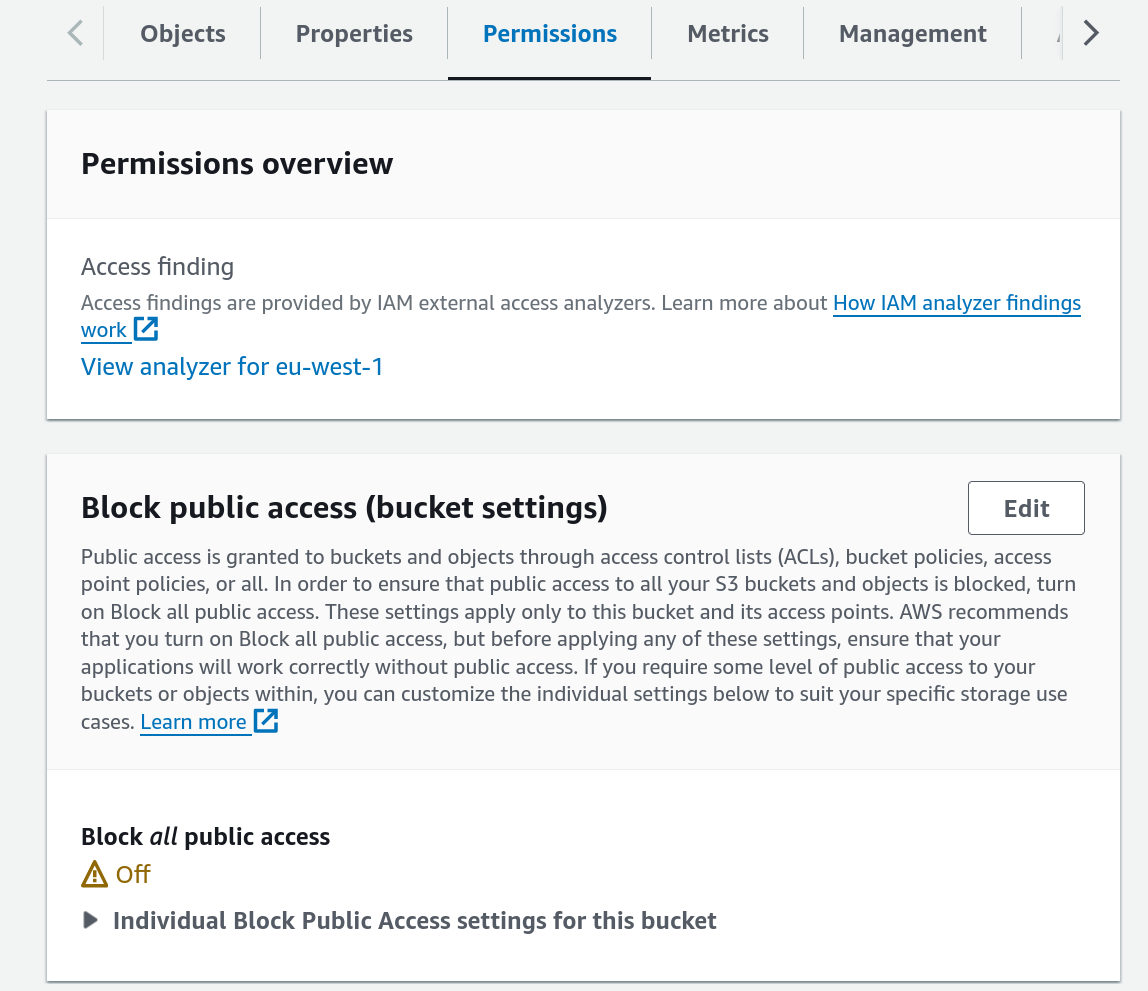
Fig. 8.18 Bucket settings allow making the bucket public¶
Alternatively, create a bucket policy as shown below, inserting your own bucket name into the two placeholders:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": [
"arn:aws:s3:::YOUR-BUCKET-NAME-HERE",
"arn:aws:s3:::YOUR-BUCKET-NAME-HERE/*"
]
}
]
}
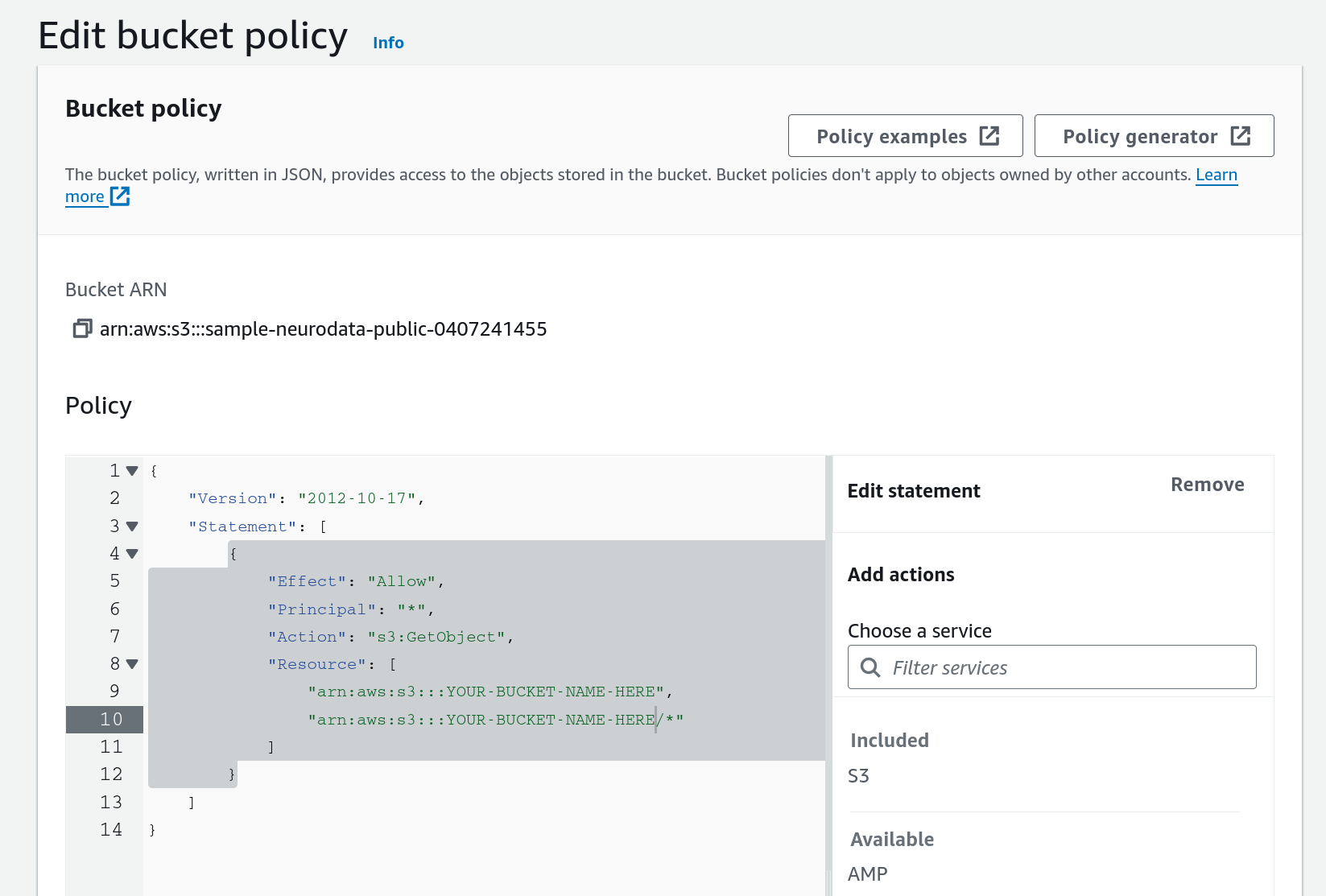
Fig. 8.19 Bucket policy to allow objects in the bucket to be retrieved by anyone.¶
Info on public buckets created prior to April 2023
Amazon S3 buckets created before April 2023 supported using ACLs for public read access to files.
This functionality has since been deprecated, and only remains for legacy buckets.
When dealing with an old S3 bucket using ACLs like that, it is possible to use the deprecated public parameter and set it to “yes”.
public=yes: Set to “yes” to allow public read access to files sent to the S3 remote
Lastly, for git-annex to be able to download files from the bucket without requiring your AWS credentials, it needs to know where to find the bucket. We do this by setting the bucket URL, which takes a standard format incorporating the bucket name and location (see the code block below). Alternatively, this URL can also be copied from your AWS console.
$ git annex enableremote public-s3 \
publicurl="https://$BUCKET.s3.dualstack.eu-west-1.amazonaws.com"
enableremote public-s3 ok
(recording state in git...)
8.4.4. Publish the dataset¶
The special remote is ready, and now we want to give people seamless access to the
DataLad dataset. A common way to do this is to create a sibling of the dataset on
GitHub using datalad create-sibling-github (manual). In order to link the contents in the
S3 special remote to the GitHub sibling, we also need to configure a publication
dependency to the public-s3 sibling, which is done with the publish-depends <sibling>
option. For consistency, we’ll give the GitHub repository the same name as the dataset name.
$ datalad create-sibling-github -d . neuro-data-s3 \
--publish-depends public-s3 --access-protocol ssh
[INFO ] Configure additional publication dependency on "public-s3"
.: github(-) [https://github.com/jsheunis/sample-neuro-data.git (git)]
'https://github.com/jsheunis/sample-neuro-data.git' configured as sibling 'github' for Dataset(/Users/jsheunis/Documents/neuro-data-s3)
Notice that by creating this sibling, DataLad created an actual (empty) dataset repository on GitHub, which required preconfigured GitHub authentication details.
The creation of the sibling (named github) can also be confirmed with datalad siblings:
$ datalad siblings
.: here(+) [git]
.: public-s3(+) [git]
.: github(-) [https://github.com/jsheunis/neuro-data-s3.git (git)]
The next step is to actually push the file content to where it needs to be in order
to allow others to access the data. We do this with datalad push --to github (manual).
The --to github specifies which sibling to push the dataset to, but because of the
publication dependency DataLad will push the annexed contents to the special remote first.
$ datalad push --to github
copy(ok): CHANGES (file) [to public-s3...]
copy(ok): README (file) [to public-s3...]
copy(ok): dataset_description.json (file) [to public-s3...]
copy(ok): sub-01/anat/sub-01_T1w.nii (file) [to public-s3...]
copy(ok): sub-01/func/sub-01_task-auditory_bold.nii (file) [to public-s3...]
copy(ok): sub-01/func/sub-01_task-auditory_events.tsv (file) [to public-s3...]
copy(ok): task-auditory_bold.json (file) [to public-s3...]
publish(ok): . (dataset) [refs/heads/main->github:refs/heads/main [new branch]]
publish(ok): . (dataset) [refs/heads/git-annex->github:refs/heads/git-annex [new branch]]
You can now view the annexed file content (with MD5 hashes as filenames) in the S3 bucket:
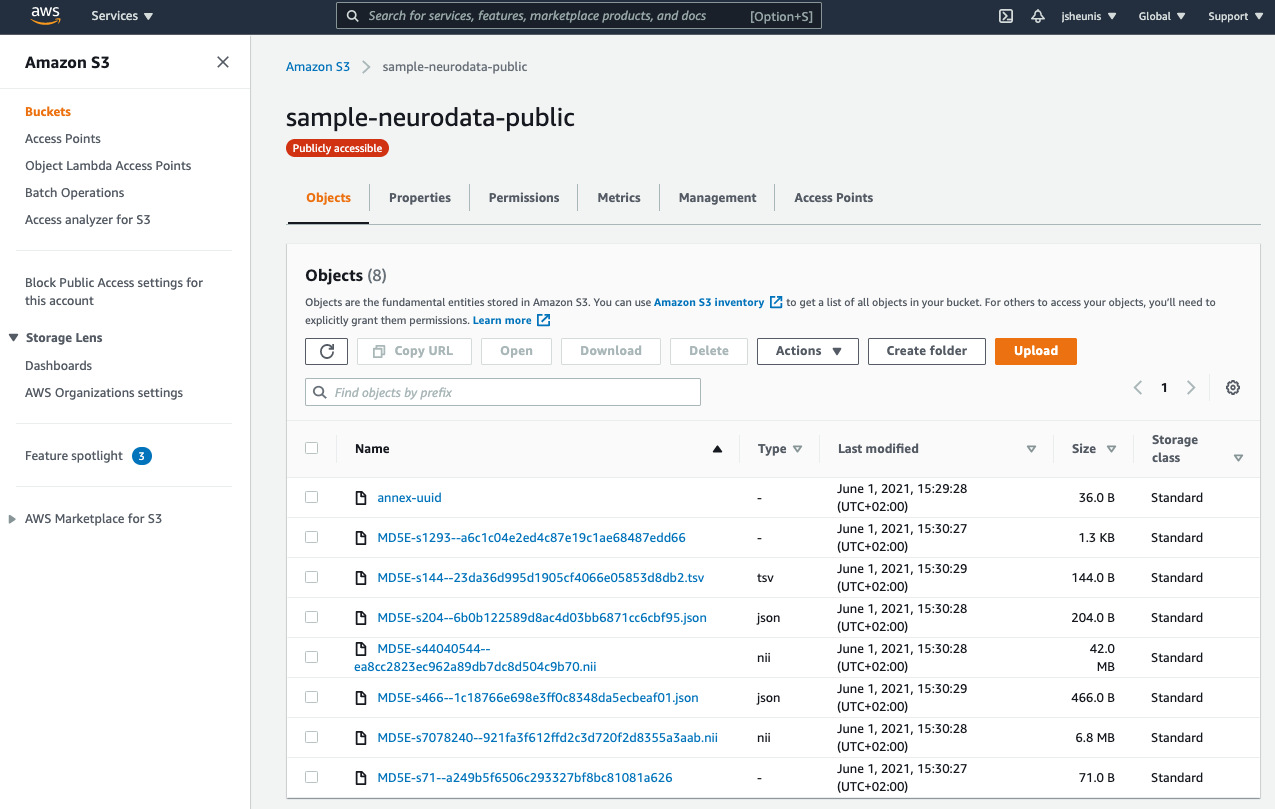
Fig. 8.20 The public S3 bucket with annexed file content pushed¶
Lastly, the GitHub repository will also show the newly pushed dataset (with the “files” being symbolic links to the annexed content on the S3 remote):
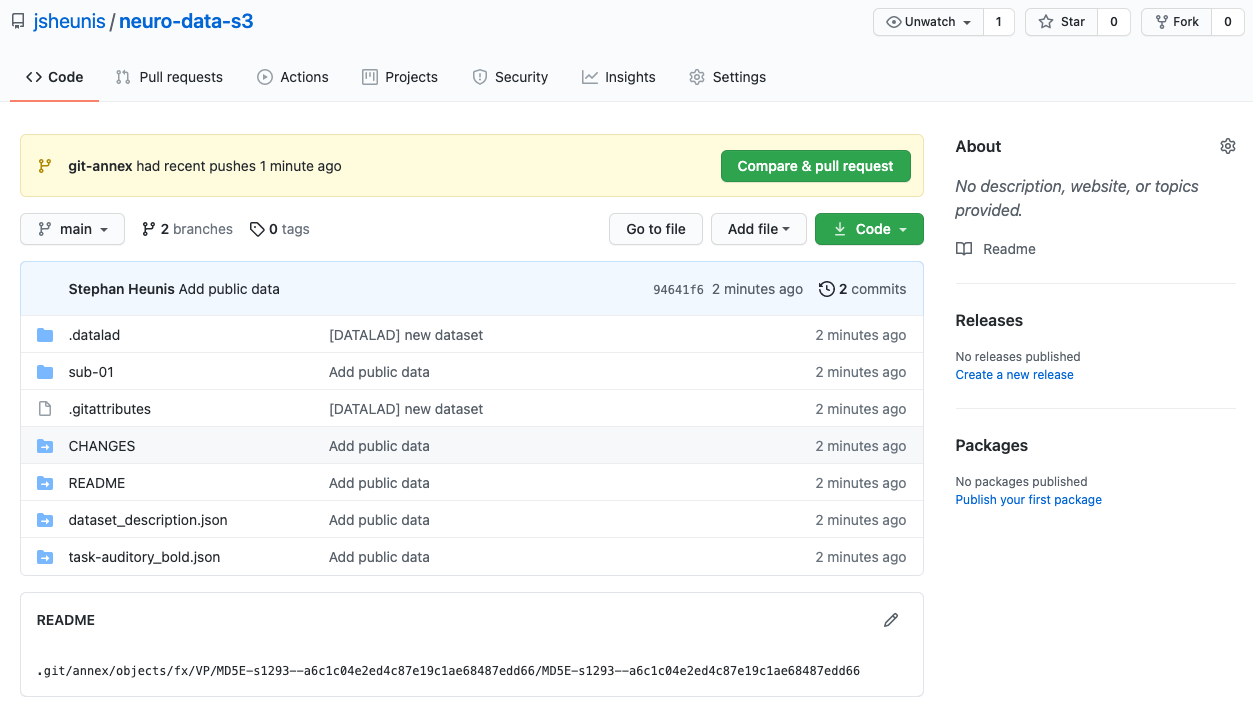
Fig. 8.21 The public GitHub repository with the DataLad dataset¶
8.4.5. Test the setup!¶
You have now successfully created a DataLad dataset with an AWS S3 special remote for
annexed file content and with a public GitHub sibling from which the dataset can be accessed.
Users can now datalad clone (manual) the dataset using the GitHub repository URL:
$ cd /tmp
$ datalad clone https://github.com/<enter-your-your-organization-or-account-name-here>/neuro-data-s3.git
[INFO ] Scanning for unlocked files (this may take some time)
[INFO ] Remote origin not usable by git-annex; setting annex-ignore
install(ok): /tmp/neuro-data-s3 (dataset)
$ cd neuro-data-s3
$ datalad get . -r
[INFO ] Installing Dataset(/tmp/neuro-data-s3) to get /tmp/neuro-data-s3 recursively
get(ok): CHANGES (file) [from public-s3...]
get(ok): README (file) [from public-s3...]
get(ok): dataset_description.json (file) [from public-s3...]
get(ok): sub-01/anat/sub-01_T1w.nii (file) [from public-s3...]
get(ok): sub-01/func/sub-01_task-auditory_bold.nii (file) [from public-s3...]
get(ok): sub-01/func/sub-01_task-auditory_events.tsv (file) [from public-s3...]
get(ok): task-auditory_bold.json (file) [from public-s3...]
action summary:
get (ok: 7)
The results of running the code above show that DataLad could datalad install (manual) the dataset correctly
and datalad get (manual) all annexed file content successfully from the public-s3 sibling.
Congrats!
8.4.6. Advanced examples - automatically export a hierarchy of datasets¶
When there is a lot to upload, automation is your friend. One example is the automated upload of dataset hierarchies to S3
The script below is a quick-and-dirty solution to the task of exporting a hierarchy of datasets to an S3 bucket. It needs to be invoked with three positional arguments, the path to the DataLad superdataset, the S3 bucket name, and a prefix.
#!/bin/bash
set -eu
export PS4='> '
set -x
topds="$1"
bucket="$2"
prefix="$3"
srname="${bucket}5"
topdsfull=$PWD/$topds/
if ! git annex version | grep 8.2021 ; then
echo "E: need recent git annex. check what you have"
exit 1
fi
{ echo "$topdsfull"; datalad -f '{path}' subdatasets -r -d "$topds"; } | \
while read ds; do
relds=$(relpath "$ds" "$topdsfull")
fileprefix="$prefix/$relds/"
fileprefix=$(python -c "import os,sys; print(os.path.normpath(sys.argv[1]))" "$fileprefix")
echo $relds;
(
cd "$ds";
# TODO: make sure that there is no ./ or // in fileprefix
if ! git remote | grep -q "$srname"; then
git annex initremote --debug "$srname" \
type=S3 \
autoenable=true \
bucket=$bucket \
encryption=none \
exporttree=yes \
"fileprefix=$fileprefix/" \
host=s3.amazonaws.com \
partsize=1GiB \
port=80 \
"publicurl=https://s3.amazonaws.com/$bucket" \
public=yes \
versioning=yes
fi
git annex export --to "$srname" --jobs 6 main
)
done
8.4.7. Advanced examples - configure s3 via terraform¶
If you are using terraform or tofu for managing AWS configuration, you can add an S3 bucket with public read access using this snippet (replacing my-example-bucket with the intended bucket name):
resource "aws_s3_bucket" "datalad_bucket" {
bucket = "my-example-bucket"
}
resource "aws_s3_bucket_public_access_block" "datalad_bucket_enable_public_read" {
bucket = aws_s3_bucket.datalad_bucket.id
block_public_policy = false
ignore_public_acls = false
restrict_public_buckets = false
}
resource "aws_s3_bucket_policy" "datalad_bucket_read_publicly_policy" {
depends_on = [aws_s3_bucket_public_access_block.datalad_bucket_enable_public_read]
bucket = aws_s3_bucket.datalad_bucket.id
policy = jsonencode({
"Version" : "2012-10-17",
"Statement" : [{
"Principal": "*",
"Action" : [
"s3:GetObject",
"s3:ListBucket"
],
"Resource" : [
aws_s3_bucket.datalad_bucket.arn,
"${aws_s3_bucket.datalad_bucket.arn}/*",
]
"Effect" : "Allow",
}]
})
}