8.6. Walk-through: Dataset hosting on GIN¶
GIN (G-Node infrastructure) is a free data management system designed for comprehensive and reproducible management of scientific data. It is a web-based repository store and provides fine-grained access control to share data. GIN builds up on Git and git-annex, and is an easy alternative to other third-party services to host and share your DataLad datasets[1]. It allows to share datasets and their contents with selected collaborators or making them publicly and anonymously available. And even if you prefer to expose and share your datasets via GitHub, you can still use GIN to host your data.

Fig. 8.22 Some repository hosting services such as GIN have annex support, and can thus hold the complete dataset. This makes publishing datasets very easy.¶
8.6.1. Prerequisites¶
In order to use GIN for hosting and sharing your datasets, you need to
register
upload your public SSH key for SSH access
Once you have registered an account on the GIN server by providing your e-mail address, affiliation, and name, and selecting a user name and password, you should upload your SSH key to allow SSH access (you can find an explanation of what SSH keys are and how you can create one in this Findoutmore in the general section Publishing datasets to Git repository hosting). To do this, visit the settings of your user account. On the left hand side, select the tab “SSH Keys”, and click the button “Add Key”:
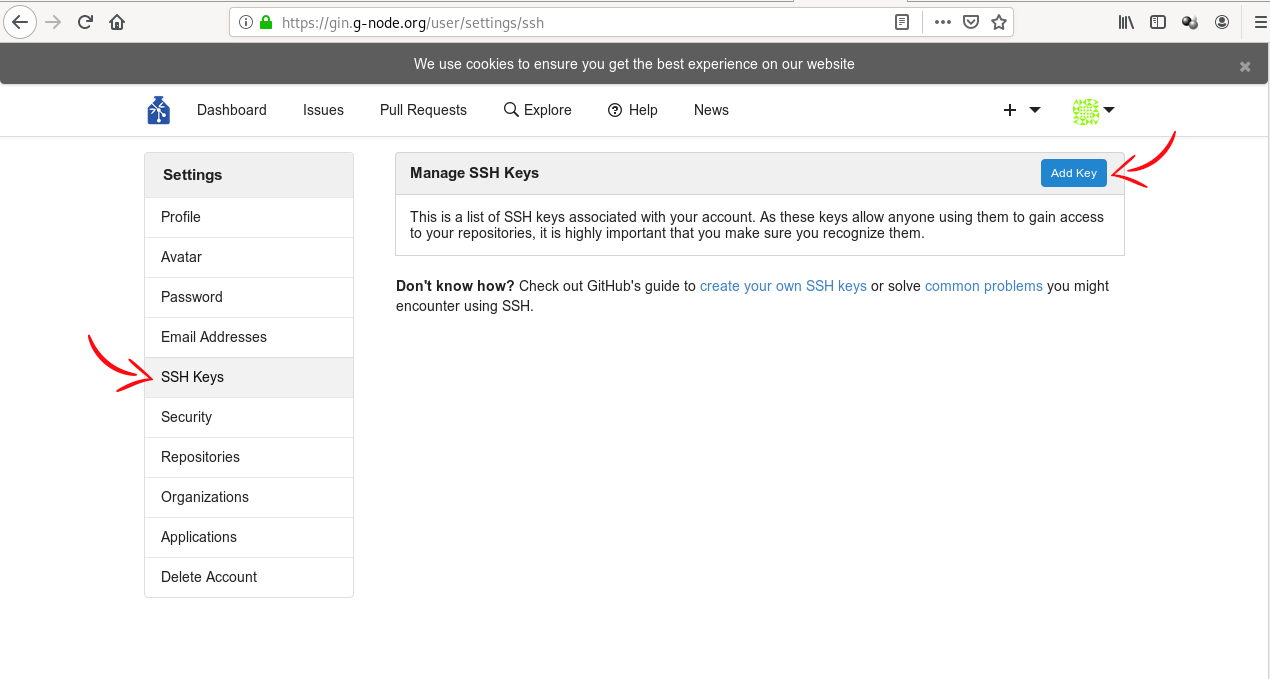
Fig. 8.23 Upload your SSH key to GIN¶
You should copy the contents of your public key file into the field labeled
content, and enter an arbitrary but informative Key Name, such as
“My private work station”. Afterwards, you are done!
8.6.2. Publishing your dataset to GIN¶
As outlined in the section Publishing datasets to Git repository hosting, there are two ways in which you can publish your dataset to GIN.
Either by 1) creating a new, empty repository on GIN via the web interface, or 2) via the datalad create-sibling-gin (manual) command.
1) via webinterface: If you choose to create a new repository via GIN’s web interface, make sure to not initialize it with a README:
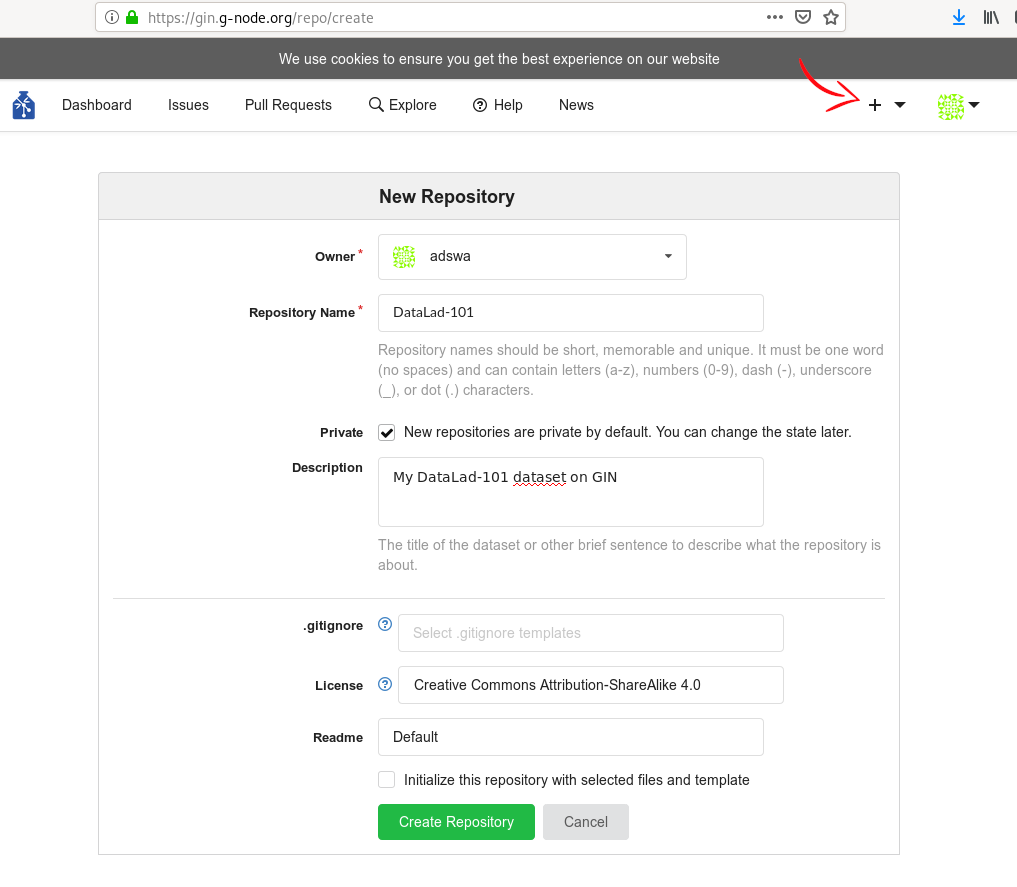
Fig. 8.24 Create a new repository on GIN using the web interface.¶
Afterwards, add this repository as a sibling of your dataset. To do this, use the
datalad siblings add (manual) command and the SSH URL of the repository as shown below.
Note that since this is the first time you will be connecting to the GIN server
via SSH, you will likely be asked to confirm to connect. This is a safety measure,
and you can type “yes” to continue:
$ datalad siblings add -d . \
--name gin \
--url git@gin.g-node.org:/adswa/DataLad-101.git
The authenticity of host 'gin.g-node.org (141.84.41.219)' can't be established.
ECDSA key fingerprint is SHA256:E35RRG3bhoAm/WD+0dqKpFnxJ9+yi0uUiFLi+H/lkdU.
Are you sure you want to continue connecting (yes/no)? yes
[INFO ] Failed to enable annex remote gin, could be a pure git or not accessible
[WARNING] Failed to determine if gin carries annex.
.: gin(-) [git@gin.g-node.org:/adswa/DataLad-101.git (git)]
2) via command-line:
If you choose to use the datalad create-sibling-gin command, supply the command with a name for the repository, and optionally add a -s/--siblingname [NAME] parameter (if unconfigured it will be gin), and --access-protocol [https|ssh|https-ssh] (ideally ssh).
The command has a number of additional useful parameters, so make sure to take a look at its --help.
Afterwards, you can publish your dataset with datalad push (manual). As the
repository on GIN supports a dataset annex, there is no publication dependency
to an external data hosting service necessary, and the dataset contents
stored in Git and in git-annex are published to the same place:
$ datalad push --to gin
copy(ok): books/TLCL.pdf (file) [to gin...]
copy(ok): books/bash_guide.pdf (file) [to gin...]
copy(ok): books/byte-of-python.pdf (file) [to gin...]
copy(ok): books/progit.pdf (file) [to gin...]
publish(ok): . (dataset) [refs/heads/git-annex->gin:refs/heads/git-annex ✂FROM✂..✂TO✂]
publish(ok): . (dataset) [refs/heads/main->gin:refs/heads/main [new branch]]
On the GIN web interface you will find all of your dataset – including annexed contents! What is especially cool is that the GIN web interface (unlike GitHub) can even preview your annexed contents.
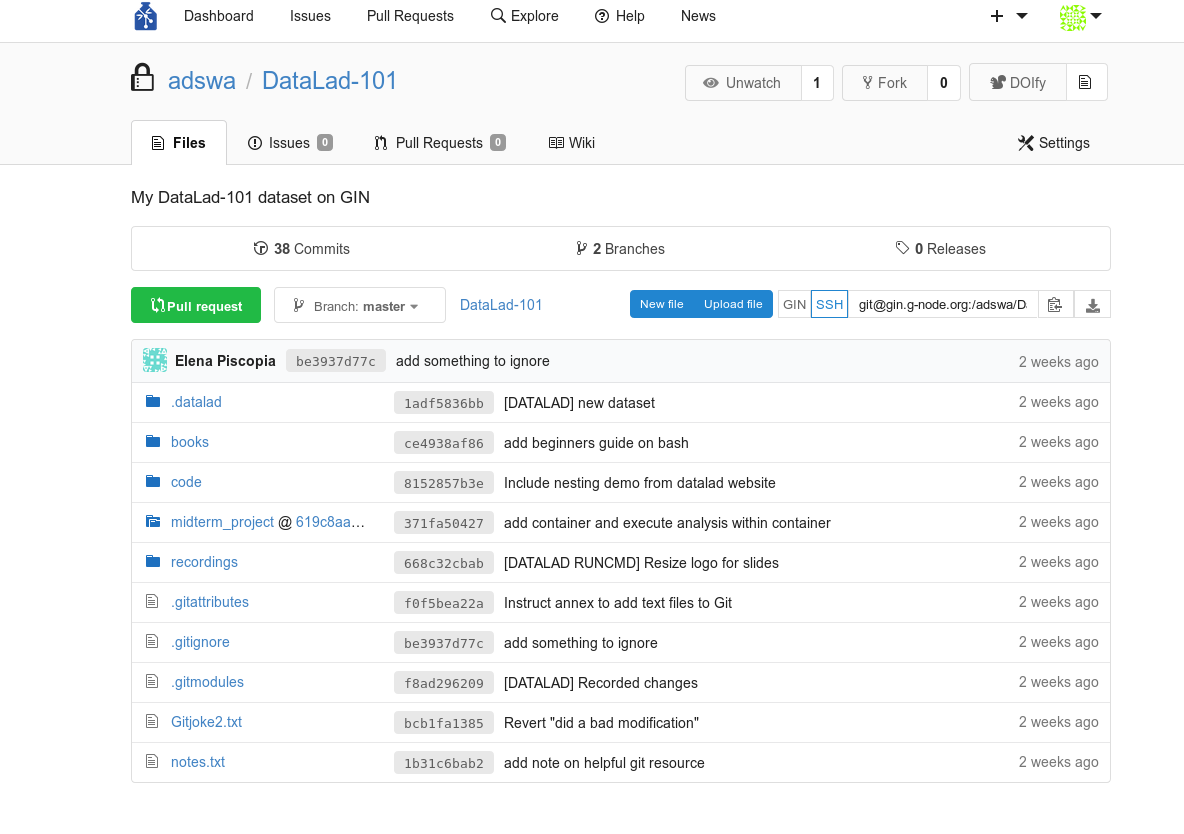
Fig. 8.25 A published dataset in a GIN repository at gin.g-node.org.¶
8.6.3. Sharing and accessing the dataset¶
Once your dataset is published, you can point collaborators and friends to it.
If it is a public repository, retrieving the dataset and getting access to
all published data contents (in a read-only fashion) is done by cloning the
repository’s https url. This does not require a user account on GIN.
Take the URL in the browser, not the copy-paste URL
Please note that you need to use the browser URL of the repository, not the copy-paste URL on the upper right hand side of the repository if you want to get anonymous HTTPS access!
The two URLs differ only by a .git extension:
Browser bar:
https://gin.g-node.org/<user>/<repo>Copy-paste “HTTPS clone”:
https://gin.g-node.org/<user>/<repo>.git
A dataset cloned from https://gin.g-node.org/<user>/<repo>.git, however, cannot retrieve annexed files!
$ datalad clone https://gin.g-node.org/adswa/DataLad-101
install(ok): /home/me/dl-101/clone_of_dl-101/DataLad-101 (dataset)
Subsequently, datalad get (manual) calls will be able to retrieve all annexed
file contents that have been published to the repository.
If it is a private dataset, cloning the dataset from GIN requires a user name and password for anyone you want to share your dataset with. The “Collaboration” tab under Settings lets you set fine-grained access rights, and it is possible to share datasets with collaborators that are not registered on GIN with provided Guest accounts. If you are unsure if your dataset is private, this find-out-more shows you how to find out. In order to get access to annexed contents, cloning requires setting up an SSH key as detailed above, and cloning via the SSH url:
$ datalad clone git@gin.g-node.org:/adswa/DataLad-101.git
Likewise, in order to publish changes back to a GIN repository, the repository needs to be cloned via its SSH url.
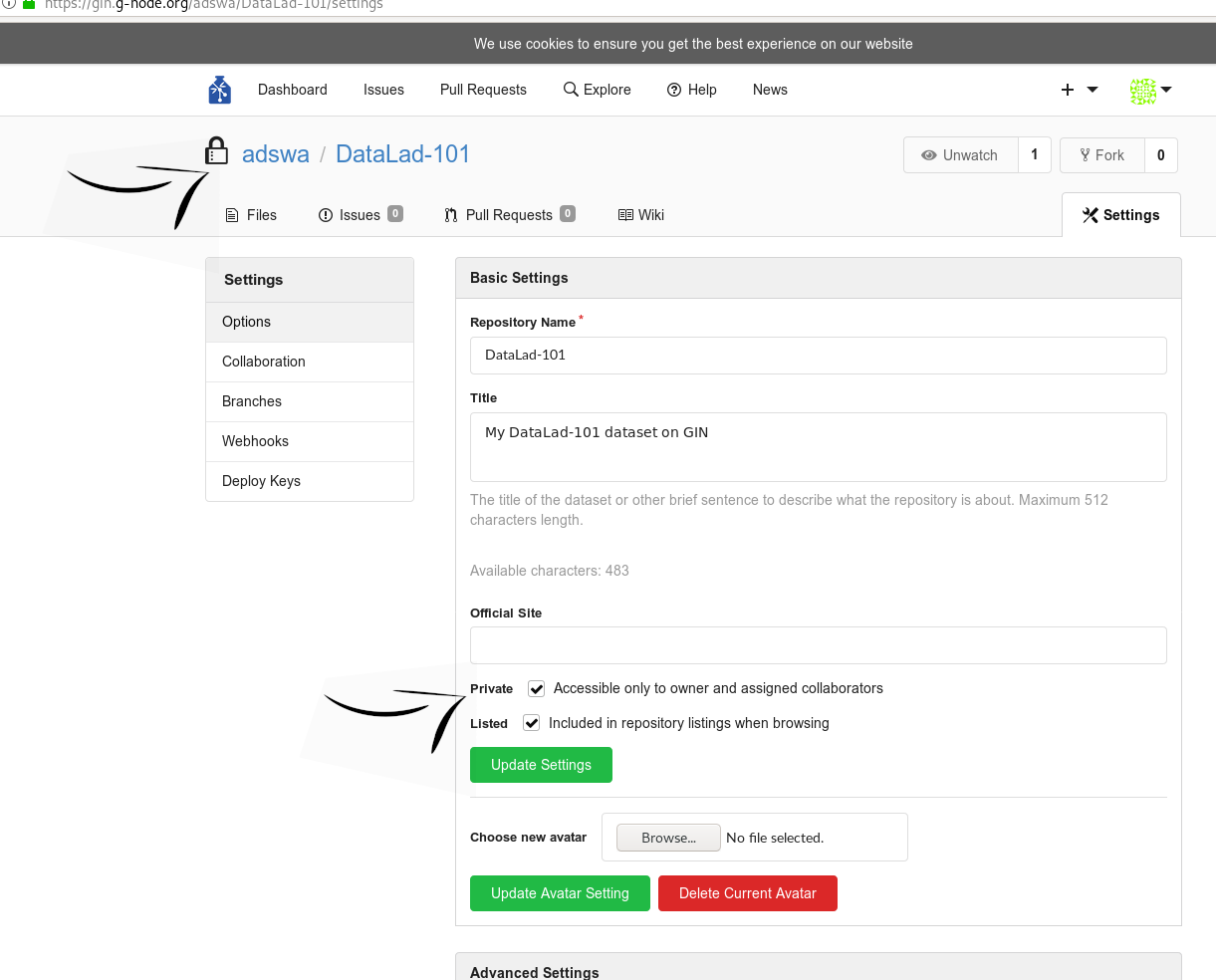
How do I know if my repository is private?
Private repos are marked with a lock sign. To make it public, untick the “Private” box, found under “Settings”:
8.6.4. Subdataset publishing¶
Just as the input subdataset iris_data in your published midterm_project
was referencing its source on GitHub, the longnow subdataset in your
published DataLad-101 dataset directly references the original
dataset on GitHub. If you click onto recordings and then longnow in GIN’s webinterface, you will
be redirected to the podcast’s original dataset.
The subdataset midterm_project, however, is not successfully referenced. If
you click on it, you would get to a 404 Error page. The crucial difference between this
subdataset and the longnow dataset is its entry in the .gitmodules file of
DataLad-101:
$ cat .gitmodules
[submodule "recordings/longnow"]
path = recordings/longnow
url = https://github.com/datalad-datasets/longnow-podcasts.git
datalad-id = b3ca2718-8901-11e8-99aa-a0369f7c647e
[submodule "midterm_project"]
path = midterm_project
url = ./midterm_project
datalad-id = e5a3d370-223d-11ea-af8b-e86a64c8054c
While the longnow subdataset is referenced with a valid URL to GitHub, the midterm
project’s URL is a relative path from the root of the superdataset. This is because
the longnow subdataset was installed with datalad clone -d . (manual)
(that records the source of the subdataset), and the midterm_project dataset
was created as a subdataset with datalad create -d . midterm_project (manual).
Since there is no repository at
https://gin.g-node.org/<USER>/DataLad-101/midterm_project (which this submodule
entry would resolve to), accessing the subdataset fails.
However, since you have already published this dataset (to GitHub), you could
update the submodule entry and provide the accessible GitHub URL instead. This
can be done via the set-property <NAME> <VALUE> option of
datalad subdatasets (manual)[2] (replace the URL shown here with the URL
your dataset was published to – likely, you only need to change the user name):
$ datalad subdatasets --contains midterm_project \
--set-property url https://github.com/adswa/midtermproject
add(ok): .gitmodules (file)
save(ok): . (dataset)
subdataset(ok): midterm_project (dataset)
$ cat .gitmodules
[submodule "recordings/longnow"]
path = recordings/longnow
url = https://github.com/datalad-datasets/longnow-podcasts.git
datalad-id = b3ca2718-8901-11e8-99aa-a0369f7c647e
datalad-url = https://github.com/datalad-datasets/longnow-podcasts.git
[submodule "midterm_project"]
path = midterm_project
url = https://github.com/adswa/midtermproject
datalad-id = d95bafc8-f2a4-d27b-dcf4-bb99f4bea973
Handily, the datalad subdatasets command saved this change to the
.gitmodules file automatically and the state of the dataset is clean:
$ datalad status
nothing to save, working tree clean
Afterwards, publish these changes to gin and see for yourself how this fixed
the problem:
$ datalad push --to gin
publish(ok): . (dataset) [refs/heads/main->gin:refs/heads/main 7dd7551..445460d]
action summary:
publish (notneeded: 1, ok: 1)
If the subdataset was not published before, you could publish the subdataset to
a location of your choice, and modify the .gitmodules entry accordingly.
8.6.5. Using GIN as a data source behind the scenes¶
Even if you do not want to point collaborators to yet another hosting site but want to be able to expose your datasets via services they use and know already (such as GitHub or GitLab), GIN can be very useful: You can let GIN perform data hosting in the background by using it as an “autoenabled data source” that a dataset sibling (even if it is published to GitHub or GitLab) can retrieve data from. You will need to have a GIN account and SSH key setup, so please take a look at the first part of this section if you do not yet know how to do this.
Then, follow these steps:
First, create a new repository on GIN (see step by step instructions above).
In your to-be-published dataset, add this repository as a sibling, this time setting –url and –pushurl arguments explicitly. Make sure to configure a SSH URL as a
--pushurlbut a HTTPS URL as aurl. Please also note that the HTTPS URL written after--urlDOES NOT have the.gitsuffix. Here is the command:
$ datalad siblings add \
-d . \
--name gin \
--pushurl git@gin.g-node.org:/studyforrest/aggregate-fmri-timeseries.git \
--url https://gin.g-node.org/studyforrest/aggregate-fmri-timeseries \
Locally, run
git config --unset-all remote.gin.annex-ignoreto prevent git-annex from ignoring this new datasetPush your data to the repository on GIN (
datalad push --to gin). This pushes the actual state of the repository, including content, but also adjusts the git-annex configuration.Configure this sibling as a “common data source”. Use the same name as previously in
--name(to indicate which sibling you are configuring) and give a new, different, name after--as-common-datasrc:
$ datalad siblings configure \
--name gin \
--as-common-datasrc gin-src
Push to the repository on GIN again (
datalad push --to gin) to make the configuration change known to the Gin sibling.Publish your dataset to GitHub/GitLab/…, or update an existing published dataset (
datalad push)
Afterwards, datalad get retrieves files from GIN, even if the dataset has been cloned from GitHub.
Siblings as a common data source
The argument as-common-datasrc <name> configures a sibling as a common data source – in technical terms, as an auto-enabled git-annex special remote.
Footnotes